![[PukiWiki]](image/pukiwiki.png "[PukiWiki]")
卒論テーマが決まった。
耐候性鋼橋の耐候性鋼材の錆の現地調査(今年度から)(日本鉄鋼連盟、土木研究センター、東北の大学や高専の土木構造系研究室の共同研究)に参加しながら、撮影データに対して機械学習(AI)を用いた外観評価を行う。最終的にドローンで撮影した耐候性鋼橋の画像データに対して外観評点を行う方法も検討する(特定の距離や照明で撮影するといった制御ができるか)。
--佐藤さんの卒論日誌をはじめ耐候性鋼材にまつわるウィキを読んで分からなかった部分をリストアップする。ただ何が分かっていないか分からない 来週のゼミ報告に向けてなにか目標をたてなければ
画像: ファイル名(.ppm) | クリック位置: (x座標, y座標), RGB値: (R(0~255), G(0~255), B(0~255),)と表示される。またフォルダーパスの入力をしたファイル内に4で保存したファイルが保存されている(今回はhome/kouzou/sato24/gr/data/1_ppm に RGBsyuturyoku0423 というの文書ファイルが保存されている)

 →
→ 
--残りのPythonファイルについて使い方を学ぶ

この写真の場合 "mk1_pgm"等が入っている1番左にある "250_300_edge" フォルダーと1番右にある "svm-kaizou.py" が同じ階層にある。
---変換行列ファイルはかなり細かい値まで書かれているためなぜそのような値に設定したのか一度聞いてみる必要がありそう
このpythonファイルは henkan.py で必要になる変換行列ファイルを作り出すためのものであり、henkan.pyよりも先にやっておく必要がある。
---各RGB値を入力するにあたりなにか根拠となるものがあるはず(ppm画像とか) → 探しておく必要がある
Pythonコード
Pythonコード
Pythonコード

| 手順 | 実行内容 |
| 1 | 画像を入力する(ピクセルで) |
| 2 | 畳み込み層で画像の特徴を検出する |
| 3 | プーリング層で重要な情報を抽出する |
| 4 | 2と3を繰り返す |
| 5 | 全結合層で画像の特徴をもとに分類を行う |
| 6 | 出力する |
| 比較項目 | SVM | CNN |
| モデル | すでに用意された特徴(数値)をもとにクラス分けする数式モデル | 画像の中から特徴を自動で学習して分類まで行うニューラルネットワーク |
| 入力 | 数値データ (特徴量ベクトル) → 画像を数値に変換する必要あり | 生の画像そのまま(ピクセルデータ) |
| 特徴の抽出方法 | 手動(人があらかじめ決めた特徴) | 自動(エッジ・色・形などを学習) |
| モデル構造 | 数学的な式(境界面) | 多層のニューラルネットワーク |
| 適用例 | 小規模なデータで分類(例:文字分類、小さな画像) | 大規模な画像分類・認識(例:顔認識、医療画像、サビ分類など) |
| 学習の難易度 | 比較的簡単(実装も軽い) | やや難しい(GPUや深層学習の知識が必要) |
| 処理速度 | 小規模なら早い | 訓練に時間がかかる(推論は速い) |
| 学習方法 | テストデータ正答率(%) | 判別精度(%) |
| そのままの状態で画像を学習 | 99.14 | 44 (4/9) |
| 画像を回転・移動・拡大・変形させて学習 | 98.49 | 67 (6/9) |
| エポック数 | テストデータ正答率(%) | 判別精度(%) |
| 10 | 99.20 | 67 (6/9) |
| 12 | 99.13 | 56 (5/9) |
| 13 | 99.26 | 89 (8/9) |
| 14 | 99.19 | 89 (8/9) |
| 15 | 99.16 | 89 (8/9) |
| 16 | 99.08 | 89 (8/9) |
| エポック数 | テストデータ正答率(%) | 判別精度(%) |
| 10 | 95.47 | 56 (5/9) |
| 12 | 87.01 | 56 (5/9) |
| 13 | 90.55 | 56 (5/9) |
| 14 | 96.15 | 56 (5/9) |
| 15 | 86.66 | 56 (5/9) |
| 16 | 74.12 | 56 (5/9) |
| 数字 | モデル数 | 正答率 |
| 0 | 3 | 3/3 |
| 1 | 5 | 5/5 |
| 2 | 6 | 6/6 |
| 3 | 6 | 6/6 |
| 4 | 2 | 2/2 |
| 5 | 10 | 9/10 |
| 6 | 2 | 1/2 |
| 7 | 3 | 2/3 |
| 8 | 2 | 1/2 |
| 9 | 13 | 9/13 |
本来は各数字のモデル数が揃っていることが望ましいが、こちらの諸事情により用意することができなかった。モデル数が 2 や 3 としかない部分は正確さに欠ける所があるが、1 ~ 3 はかなり正確性があると言って良いのではないか。特に 9 は 7 と間違えて識別するケースが多く見受けられた。
 ー画像加工→
ー画像加工→

 ー画像加工→
ー画像加工→

 ー画像加工→
ー画像加工→

Pythonコード (Gazou-Kakou.py)
| 数字 | 正答率 | 正答率 |
| 0 | 9/9 | 9/9 |
| 1 | 8/9 | 1/9 |
| 2 | 9/9 | 6/9 |
| 3 | 9/9 | 6/9 |
| 4 | 9/9 | 0/9 |
| 5 | 9/9 | 5/9 |
| 6 | 5/9 | 2/9 |
| 7 | 8/9 | 4/9 |
| 8 | 6/9 | 6/9 |
| 9 | 6/9 | 0/9 |



| 数字 | 正答率 |
| 0 | 10/10 |
| 1 | 10/10 |
| 2 | 10/10 |
| 3 | 10/10 |
| 4 | 10/10 |
| 5 | 10/10 |
| 6 | 10/10 |
| 7 | 10/10 |
| 8 | 10/10 |
| 9 | 10/10 |









| 数字 | 点 正答率 | 線 正答率 | 図形 正答率(リスタート前) | 図形 正答率(リスタート後) |
| 0 | 10/10 | 9/10 | 8/10 | 10/10 |
| 1 | 10/10 | 4/10 | 5/10 | 6/10 |
| 2 | 10/10 | 9/10 | 8/10 | 10/10 |
| 3 | 10/10 | 7/10 | 9/10 | 10/10 |
| 4 | 10/10 | 9/10 | 8/10 | 8/10 |
| 5 | 10/10 | 9/10 | 10/10 | 10/10 |
| 6 | 8/10 | 3/10 | 1/10 | 3/10 |
| 7 | 10/10 | 7/10 | 7/10 | 8/10 |
| 8 | 10/10 | 10/10 | 10/10 | 10/10 |
| 9 | 10/10 | 7/10 | 7/10 | 6/10 |
Pythonコード (Gazou-Kakou-Ten_only.py)
Pythonコード (Gazou-Kakou-Sen_only.py)
Pythonコード (Gazou-Kakou-Zukei_only.py)



→大まかな内容は完了しこれから肉付け(5/11)
Pythonスクリプト (Hanbetsu-Full_auto.py)
| 0_7.png 予測: 0 正解: 0 一致: 〇 |
| 1_5.png 予測: 8 正解: 1 一致: × |
| 3_5.png 予測: 3 正解: 3 一致: 〇 |
| 8_2.png 予測: 8 正解: 8 一致: 〇 |
| … |
| --- 数字ごとの正答率 --- |
| 0: 正解 ○ / □ 枚 → 正答率 △ % |
| 1: 正解 △ / ○ 枚 → 正答率 □ % |
| … |
| 数字 | 正答率 | 正解率 | -正答率- | -正解率- | --正答率-- | --正解率-- |
| 0 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
| 1 | 0/10 | 0.00% | 8/10 | 80.00% | 5/10 | 50.00% |
| 2 | 10/10 | 100.00% | 5/10 | 50.00% | 10/10 | 100.00% |
| 3 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
| 4 | 6/10 | 60.00% | 4/10 | 40.00% | 5/10 | 50.00% |
| 5 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
| 6 | 0/10 | 0.00% | 0/10 | 0.00% | 3/10 | 30.00% |
| 7 | 10/10 | 100.00% | 1/10 | 10.00% | 9/10 | 90.00% |
| 8 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
| 9 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
Pythonスクリプト (Mnist-Hanbetsu-Full_auto.py)
| 数字 | 正答率 | 正解率 | -正答率- | -正解率- | --正答率-- | --正解率-- |
| 0 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
| 1 | 0/10 | 0.00% | 0/10 | 0.00% | 2/10 | 20.00% |
| 2 | 8/10 | 80.00% | 9/10 | 90.00% | 10/10 | 100.00% |
| 3 | 10/10 | 100.00% | 7/10 | 70.00% | 8/10 | 80.00% |
| 4 | 8/10 | 80.00% | 9/10 | 90.00% | 1/10 | 10.00% |
| 5 | 10/10 | 100.00% | 10/10 | 100.00% | 10/10 | 100.00% |
| 6 | 1/10 | 10.00% | 4/10 | 40.00% | 0/10 | 0.00% |
| 7 | 2/10 | 20.00% | 7/10 | 70.00% | 2/10 | 20.00% |
| 8 | 10/10 | 100.00% | 10/10 | 100.00% | 1/10 | 10.00% |
| 9 | 10/10 | 100.00% | 9/10 | 90.00% | 10/10 | 100.00% |
Pythonスクリプト (Mnist-Hanbetsu-Full_auto2.py)
| 数字 | 正答率 | 正解率 | -正答率- | -正解率- | --正答率-- | --正解率-- |
| 0 | 15/15 | 100.00% | 15/15 | 100.00% | 15/15 | 100.00% |
| 1 | 15/16 | 93.75% | 15/16 | 93.75% | 16/16 | 100.00% |
| 2 | 15/16 | 93.75% | 16/16 | 100.00% | 15/16 | 93.75% |
| 3 | 16/16 | 100.00% | 16/16 | 100.00% | 16/16 | 100.00% |
| 4 | 15/16 | 93.75% | 15/16 | 93.75% | 15/16 | 93.75% |
| 5 | 15/16 | 93.75% | 15/16 | 93.75% | 15/16 | 93.75% |
| 6 | 12/16 | 75.00% | 6/16 | 37.50% | 8/16 | 50.00% |
| 7 | 15/16 | 93.75% | 14/16 | 87.50% | 16/16 | 100.00% |
| 8 | 16/16 | 100.00% | 15/16 | 93.75% | 15/16 | 93.75% |
| 9 | 15/16 | 93.75% | 16/16 | 100.00% | 15/16 | 93.75% |
| 数字 | 正答率 | 正解率 | 正答率 | 正解率 | 正答率 | 正解率 | 正答率 | 正解率 | 正答率 | 正解率 |
| 0 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 1 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 2 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 19/20 | 95.00% |
| 3 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 4 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 5 | 19/20 | 95.00% | 20/20 | 100.00% | 18/20 | 90.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 6 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 7 | 17/20 | 85.00% | 20/20 | 100.00% | 19/20 | 95.00% | 19/20 | 95.00% | 19/20 | 95.00% |
| 8 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 9 | 19/20 | 95.00% | 18/20 | 90.00% | 19/20 | 95.00% | 18/20 | 90.00% | 20/20 | 100.00% |

Pythonスクリプト (Hanbetsu-Full_auto3.py)


 →
→



| 数字 | 正答率 | 正解率 | 正答率 | 正解率 | 正答率 | 正解率 |
| 0 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 1 | 20/20 | 100.00% | 19/20 | 95.00% | 19/20 | 95.00% |
| 2 | 20/20 | 100.00% | 20/20 | 100.00% | 19/20 | 95.00% |
| 3 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 4 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 5 | 20/20 | 100.00% | 19/20 | 95.00% | 19/20 | 95.00% |
| 6 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 7 | 19/20 | 95.00% | 19/20 | 95.00% | 20/20 | 100.00% |
| 8 | 20/20 | 100.00% | 20/20 | 100.00% | 20/20 | 100.00% |
| 9 | 20/20 | 100.00% | 19/20 | 95.00% | 20/20 | 100.00% |



自身の研究内容について
研究テーマ : 耐候性鋼橋の耐候性鋼材の錆の現地調査に参加しながら、撮影データに対して機械学習(AI)を用いた外観評価を行う。最終的にドローンで撮影した耐候性鋼橋の画像データに対して外観評点を行う方法も検討する
About his own research Research theme : While participating in a field survey of rust on weathering steel materials of weather-resistant steel bridges, he will evaluate the appearance using machine learning (AI) on the photographed data. Finally, a method to evaluate the appearance of weather-resistant steel bridges using image data taken by a drone will also be studied.
耐候性鋼材の錆の調査は来週の水曜日に行く予定であり、この研究に関しては錆のデータをもらわないと何もすることができないので現在は錆の画像をAIで外観評価する前段階として0~9までの手書き数字(mnist)をCNNを用いて学習させ、正確に判別できるかどうかを行っている。
The investigation of rust on weather resistant steel is scheduled to go next Wednesday, and since we cannot do anything about this research without receiving rust data, we are currently learning handwritten numbers (mnist) from 0 to 9 using CNN as a preliminary step to evaluate the appearance of rust images using AI to see if we can accurately identify the rust. We are now trying to see if it is possible to accurately discriminate the rust images.
1, 画像処理を加えてCNNで学習させたもの
1, The images of mnist, a data set containing nearly 60,000 handwritten digit images, were trained by CNN, and the correct answer rate was obtained by adding points, lines, circles, hexagons, and other shapes to the image to be discriminated.
使用したデータ Data used(example)
| 数字 | 正答率 | 正解率 |
| number | correct response rate | correct response rate |
| 0 | 9/9 | 9/9 |
| 1 | 8/9 | 1/9 |
| 2 | 9/9 | 6/9 |
| 3 | 9/9 | 6/9 |
| 4 | 9/9 | 0/9 |
| 5 | 9/9 | 5/9 |
| 6 | 5/9 | 2/9 |
| 7 | 8/9 | 4/9 |
| 8 | 6/9 | 6/9 |
| 9 | 6/9 | 0/9 |
2, 判別したい画像を以下のように変更し 判別する画像の加工, 判別の正誤をテキストファイルに保存するまでを1つのスクリプトにまとめた。
2, Change the image to be discriminated as follows, process the image to be discriminated, and save the correct and incorrect discriminions to a text file, all in one script.
| 数字 | 正答率 | 正解率 |
| number | correct response rate | correct response rate |
| 0 | 10/10 | 100.00% |
| 1 | 0/10 | 0.00% |
| 2 | 10/10 | 100.00% |
| 3 | 10/10 | 100.00% |
| 4 | 6/10 | 60.00% |
| 5 | 10/10 | 100.00% |
| 6 | 0/10 | 0.00% |
| 7 | 10/10 | 100.00% |
| 8 | 10/10 | 100.00% |
| 9 | 10/10 | 100.00% |
3, 2で用いたスクリプトはmnistをCNNで用いて学習させる機能を持っていなかった。そのため2のスクリプトにmnistをCNNで用いて学習させるスクリプトを追加した。それに加えて判別の正誤だけでなく数字別の正答率も出すようにした。
3, The script used in 2, did not have the ability to train mnist with CNN. Therefore, we added a script for training mnist using CNN to the script used in 2. In addition, we added the ability to produce not only the correctness of the discriminant but also the percentage of correct answers for each number.
| 数字 | 正答率 | 正解率 |
| number | correct answer rate | correct answer rate |
| 1 | 0/10 | 0.00% |
| 2 | 8/10 | 80.00% |
| 3 | 10/10 | 100.00% |
| 4 | 8/10 | 80.00% |
| 5 | 10/10 | 100.00% |
| 6 | 1/10 | 10.00% |
| 7 | 10/10 | 100.00% |
| 8 | 10/10 | 100.00% |
| 9 | 10/10 | 100.00% |
4, 判別したい画像に加工処理を施すだけでは正答率を100%に近づけるのに限界があると考え、学習データにも加工処理を施した。(mnistの画像にも点や直線, 円や六角形等の図形を加えた)
4, Since there is a limit to achieving a correct response rate close to 100% only by processing the images to be discriminated, we also processed the training data. (Points, lines, circles, hexagons, and other shapes were added to the mnist images.)
| 数字 | 正答率 | 正解率 |
| number | correct answer rate | correct answer rate |
| 0 | 15/15 | 100.00% |
| 1 | 15/16 | 93.75% |
| 2 | 15/16 | 93.75% |
| 3 | 16/16 | 100.00% |
| 4 | 15/16 | 93.75% |
| 5 | 15/16 | 93.75% |
| 6 | 12/16 | 75.00% |
| 7 | 15/16 | 93.75% |
| 8 | 16/16 | 100.00% |
| 9 | 15/16 | 93.75% |
Data used in 2-4 (example)
5, 判別したい画像をmnistから抽出したデータに変更した。2~4で使っていた数字の画像と比較して精度に差が出るのか試してみたところmnistから抽出したもののほうが精度が高かったためこちらを使うことにした。
5, The image to be discriminated was changed to the data extracted from mnist, and the accuracy of the image extracted from mnist was higher than that of the image used in steps 2~4.
| 数字 | 正答率 | 正解率 |
| number | correct answer rate | correct answer rate |
| 0 | 20/20 | 100.00% |
| 1 | 20/20 | 100.00% |
| 2 | 20/20 | 100.00% |
| 3 | 20/20 | 100.00% |
| 4 | 20/20 | 100.00% |
| 5 | 20/20 | 100.00% |
| 6 | 20/20 | 100.00% |
| 7 | 20/20 | 100.00% |
| 8 | 20/20 | 100.00% |
| 9 | 18/20 | 90.00% |
Data used(example)
6, 数字の書いてある部分(画像の中心部分)になるべく白い点を入れないようにした
6, I tried to avoid white dots in the numbered area (center of the image) as much as possible.
| 数字 | 正答率 | 正解率 |
| number | correct answer rate | correct answer rate |
| 0 | 20/20 | 100.00% |
| 1 | 20/20 | 100.00% |
| 2 | 20/20 | 100.00% |
| 3 | 20/20 | 100.00% |
| 4 | 20/20 | 100.00% |
| 5 | 20/20 | 100.00% |
| 6 | 20/20 | 100.00% |
| 7 | 19/20 | 95.00% |
| 8 | 20/20 | 100.00% |
| 9 | 20/20 | 100.00% |
Data used(example)
→
これら全てを取り込んだのが以下の Ver5.0 = Mnist-Hanbetsu-Full_auto5.py である。
Pythonコード (Mnist-Hanbetsu-Full_auto5.py)
| 数字 | 正答率 | 正解率 | 正答率 | 正解率 | 正答率 | 正解率 |
| 0 | 19/20 | 95.00% | 19/20 | 95.00% | 18/20 | 90.00% |
| 1 | 8/20 | 40.00% | 19/20 | 95.00% | 6/20 | 30.00% |
| 2 | 19/20 | 95.00% | 19/20 | 95.00% | 19/20 | 95.00% |
| 3 | 20/20 | 100.00% | 18/20 | 90.00% | 19/20 | 95.00% |
| 4 | 18/20 | 90.00% | 18/20 | 90.00% | 20/20 | 100.00% |
| 5 | 19/20 | 95.00% | 18/20 | 90.00% | 20/20 | 100.00% |
| 6 | 20/20 | 100.00% | 20/20 | 95.00% | 20/20 | 100.00% |
| 7 | 18/20 | 90.00% | 15/20 | 75.00% | 19/20 | 95.00% |
| 8 | 17/20 | 85.00% | 20/20 | 100.00% | 17/20 | 85.00% |
| 9 | 18/20 | 90.00% | 19/20 | 95.00% | 18/20 | 90.00% |
Mnist-Hanbetsu-Full_auto4.py を実行したときと比較して明らかに判別精度が落ちてしまっている。しかし下に示した混同行列をみると訓練モデルは正確に判別できている。(左側1枚がVer4.0のとき 右側3枚がVer5.0)




下記の内容が判別精度低下の主な原因ではないかと考えている。
| 要素 | モデル① | モデル② | モデル③ |
| 畳み込み層数 | 1 | 2 | 2 |
| カーネルサイズ | 3×3 | 3×3(2回) | 5×5 → 3×3 |
| プーリング | あり(1回) | あり(1回) | あり(1回) |
| Dropout | なし | あり(0.3) | あり(0.25・0.5) |
| BatchNorm | なし | あり(1回) | あり(1回) |
| 全結合層 | 64ユニット | 128ユニット | 64ユニット |
以下は全5バージョンのMnist-Hanbetsu-Full_autoを実行したときの判別率である。左から順にVer1.0(Mnist-Hanbetsu-Full_auto.py), Ver2.0(Mnist-Hanbetsu-Full_auto2.py), ... ,Ver5.0(Mnist-Hanbetsu-Full_auto5.py)と並んでいる。





以上より手書き数字の画像判別はあまり要素を盛り込みすぎることなく判別させることが重要であるのではないか。 (Ver4.0が数字の画像判別に1番適していると考える)
物体分類の判別
https://www.cs.toronto.edu/~kriz/cifar.html


左側がエポック数20, 右側がエポック数50としたがあまり精度は向上しなかった。
とりあえず
| タグ | 正答率 |
| airplane | 90.00 % |
| automobile | 100.00 % |
| bird | 85.00 % |
| cat | 80.00 % |
| deer | 95.00 % |
| dog | 55.00 % |
| frog | 95.00 % |
| horse | 100.00 % |
| ship | 100.00 % |
| truck | 95.00 % |
Pythonコード① (Animal.py)
Pythonコード② (Yobidashi.py)
Pythonコード③ (Buttai-Bunrui.py)
目標に向けて大まかなステップ
目標を達成するために
より高精度・運用向けの改善アイデア
| 評価項目 | 判別率(学習回数1回) | 判別率(学習回数60回) |
| airplane | 74.20% | 86.80% |
| automobile | 77.90% | 83.40% |
| bird | 43.00% | 80.00% |
| cat | 55.10% | 62.80% |
| deer | 67.60% | 85.30% |
| dog | 45.90% | 76.90% |
| frog | 66.40% | 89.40% |
| horse | 74.90% | 88.80% |
| ship | 76.00% | 92.50% |
| truck | 78.70% | 92.00% |
| 平均 | 65.97% | 83.79% |
自作したスクリプトが正常に動作するかどうかを調べたかったため、学習させる層を1層として実行させた。問題なく実行できた後は学習回数を60回にしてみてどのくらい精度が変化するのか見た。全10項目において判別精度は平均して凡そ18ポイント上昇したが、特に bird, cat, dog はもう少し精度を上げることはできないだろうか。また21日の午後は耐候性鋼材の講習会に参加した。
学習させたデータをもとに cifar10 上にあるテスト用画像を各項目100枚ずつ無作為に抽出してどのくらいの精度が得られるか検証した。以下はエポック数(= 学習回数)を変えながら行った項目ごとの判別率と判別に用いた画像である(抜粋)。










| 評価項目 | 判別率(学習回数1回) | 判別率(学習回数10回) | 判別率(学習回数30回) | 判別率(学習回数60回) |
| airplane | 73.00 % | 100.00 % | 100.00 % | 88.20 % |
| automobile | 84.00 % | 100.00 % | 100.00 % | 74.50 % |
| bird | 53.00 % | 100.00 % | 100.00 % | 76.50 % |
| cat | 68.10 % | 100.00 % | 100.00 % | 58.90 % |
| deer | 71.60 % | 100.00 % | 100.00 % | 86.70 % |
| dog | 44.00 % | 100.00 % | 99.00 % | 75.80 % |
| frog | 69.00 % | 100.00 % | 100.00 % | 91.10 % |
| horse | 79.00 % | 100.00 % | 100.00 % | 90.10 % |
| ship | 83.00 % | 100.00 % | 100.00 % | 93.40 % |
| truck | 89.70 % | 100.00 % | 100.00 % | 91.10 % |
| 平均 | 71.30% | 100.00 % | 99.90% | 82.63 % |
5/23現在エポック数を60にして判別した結果は記載していないが、エポック数が10でもかなり良い精度が出ているのでこれから学習をさせるには10とか12で良さそう。
錆の一例


過去の先輩が残してくださったセロハン試験の画像データがあったので、400ピクセル四方に切り取って学習させてみる。 以下の画像はUMAPという高次元データを低次元空間に圧縮し、データの構造や関係性を可視化するために用いられる次元削減手法を用いて錆の画像にパターンがあるかどうかを示したものである。

この図から分かること
UMAPは錆の画像に評点をつけてから使うこととする。評点をつけ終えたらクラスタ別にフォルダーを作成してどのような分布になっているのかを確かめる。
5/29 やること
昨日UMAPによって分類された錆の画像からグループ毎に10枚 合計50枚の画像に評点を書き加えた。判断方法は画像と錆の見本写真・サンプルを見比べたため正確にできているかどうか怪しいが、とりあえず作成したスクリプトが実行されるかどうかを試したいため正確さは後回し。評点ごとの枚数は以下の通り
| 評点 | 枚数 |
| 1 | 6枚 |
| 2 | 12枚 |
| 3 | 15枚 |
| 4 | 9枚 |
| 5 | 8枚 |




評点付きの錆画像データを見つけたのでこれをUMAPを用いて分類した結果を以下に示す。

2方向のUMAPはそれぞれ何を基に分類を行っているか確認してみた。以下の画像群はUMAPと aspect_ratio, sobel_x, sobel_y, orientation_std, num_blobs, roughness との間に相関関係があるかどうかを表したものである。左側がUMAP1, 右側がUMAP2となっている。












| 特徴量名 | 説明 | 数字の大小で何が分かるか |
| aspect_ratio | 縦方向エッジ量 ÷ 横方向エッジ量(= Sobel Y / Sobel X) | 値が大きいほど縦方向模様が強い(縦筋・縦のび)傾向にある |
| sobel_x | 横方向(左右)の輪郭強度(エッジ) | 値が大きいほど横縞や横模様が多い |
| sobel_y | 縦方向(上下)の輪郭強度(エッジ) | 値が大きいほど縦縞や縦模様が多い |
| orientation_std | 画像内の輪郭や模様の方向性のばらつき(標準偏差) | 値が小さいほど方向が揃っており、値が大きいほどランダム・雑多な模様 |
| num_blobs | 二値化画像から検出された「斑点」や「模様のかたまり」の数 | 多いと細かい斑点が密集しており、少ないと大きな斑模様 |
| roughness | 周辺の濃淡変化の激しさや表面のざらつき度(局所コントラストなどで算出) | 値が大きいと表面が粗くざらついた錆であり、小さいと滑らかで均一 |
| 軸 | 表すものの傾向 |
| UMAP1 | 主に「模様の強さ(エッジ強度)」+「表面の粗さ(roughness)」 |
| UMAP2 | 主に「模様の方向性のバラバラ度合い(orientation_std)」 |
このことから、UMAPプロット上で:
といった分布傾向が読み取れる。
1回の学習ごとに手動で評点を入力してはの繰り返しだと終わりが見えない&精度を上げるのに限界を感じたため別のアプローチで判別することを試みた。
評点付きの錆画像は何枚か同じ画像が存在したため重複していたものを削除したら全74枚あった錆画像が24枚(評点1から順番に 3 , 7 , 6 , 6 , 2枚)となってしまった。この枚数で機械学習させるには無理があるため、評点付きの錆画像に様々な処理を加えることで機械学習させる画像の枚数を増やしていくことにした。以下に具体的な処理とその内容について表形式で示しておく。
| 処理 | 内容 |
| 画像の反転 | ただ画像を鏡写しにするだけ |
| 画像の回転 | ランダムで ±10°~±30°、±90°、±180°のいずれかを行なう |
| 類似画像の削除 | 画像処理分野で画像の類似度を数値化する際に用いられるSSIMを使用 |
MMLI (=More Machine Learning Images).py … 既存の画像を反転・回転等で学習させる画像枚数を増やすスクリプトのこと。
Hyoutenhuriwake+UMAP2.py … ラベル付きの画像を学習させた結果をもとに画像の評点をつける。 あとUMAP画像の表示
上記のPythonスクリプトを実行させると24枚しかなかった画像を970枚近くまで増やすことができた。(SSIM=0.99のとき)このデータをUMAPを用いてグループ分けすると以下のようになった。

以前よりもクラスタリング精度が向上したのではないか。
Main.py ーー軽量化ー> Main2.py
3パターンのCNNは以下の通り
# === CNN構造定義(バリエーションを3通り用意) ===
def create_model(version):
model = models.Sequential() # 順次積み重ねるタイプのモデル(Sequential)を作成。
model.add(layers.Input(shape=(*IMAGE_SIZE, 3))) #入力層を定義。IMAGE_SIZE = (64, 64) なら、入力は 64x64x3 のカラー画像(RGB)。
if version == 0: (パターン1)
model.add(layers.Conv2D(64, (3,3), activation='relu')) #64個の3×3フィルターで特徴抽出。ReLUで非線形性を付加。
model.add(layers.BatchNormalization()) #出力を正規化し、学習の安定化と高速化を図る。
model.add(layers.Conv2D(64, (3,3), activation='relu')) #さらに抽出を深める。
model.add(layers.MaxPooling2D((2,2))) #空間サイズを半分に圧縮(特徴量の要約+計算コスト削減)
model.add(layers.Dropout(0.3)) #学習時にランダムに30%のノードを無効化(過学習防止)
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(128, (3,3), activation='relu')) #フィルター数を128に増やして、抽出する特徴の数を増加 (サイズは減っているが、意味的に濃い特徴を取る)
elif version == 1: (パターン2)
model.add(layers.Conv2D(64, (5,5), activation='relu')) #5×5の大きめフィルターで広い範囲の特徴を捉える
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Dropout(0.3)) #正規化 → 縮小 → Dropout(典型的な畳み込みブロック)
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.BatchNormalization())
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Dropout(0.3)) #より深い特徴を抽出し、再び圧縮。Dropoutを通して過学習に強い深層CNNに。
elif version == 2: (パターン3)
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.Conv2D(64, (3,3), activation='relu')) #同じフィルター数で畳み込みを2回繰り返すことで、非線形表現力を高める
model.add(layers.BatchNormalization())
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Dropout(0.3)) #出力を安定させて縮小し、汎化能力を保つ。
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.BatchNormalization()) #より抽象度の高い情報を取り出す2段構成。
model.add(layers.GlobalAveragePooling2D()) #各チャンネルの特徴マップを平均化して、全結合層の前処理を簡潔に行う。Flattenより軽量。
model.add(layers.Dense(128, activation='relu')) #最終的な判断のための全結合層
model.add(layers.Dropout(0.5)) #強めのDropoutで過学習防止
model.add(layers.Dense(NUM_CLASSES, activation='softmax')) #クラス数(評点1〜5)に対応した出力層。確率で予測を出す。
model.compile(optimizer='adam', #Adam:最もよく使われる最適化手法
loss='sparse_categorical_crossentropy', #sparse_categorical_crossentropy:ラベルが数値 (0〜4) のときの多クラス分類用損失関数
metrics=['accuracy']) #accuracy:精度(正答率)を指標として追跡
return model






従来はラベルの付いた画像をそのまま学習させていたが、判別が上手く行かないため何か特徴量で分類したほうが良いのではないかと考えた。
RSRC.py (rust_score_regression_cluster.py)
→ 錆画像にラベルをつける際に判断材料となるであろう錆の粒径, 色の濃さ, 錆が画像に占める割合, 錆の数, 画像内にある1番大きな錆と1番小さな錆の面積差の計5つの項目について、ある特徴量(前に示した5つの判断材料とは異なる)によって5グループに分けられたクラスタ(縦軸)と、実際の評点(横軸)との対応関係を可視化するスクリプト。以下に結果(各クラスタは評点1~5の画像でそれぞれどのくらい構成されているか)を示す。





以上よりクラスタ2のように明確に分類できているものもあったが全体的に見ると少数派で、クラスタが様々な評点で構成されている方が多くやはり錆に現れる特徴でラベル分けを行なうのは現時点で難しいことが分かった。正確かつ膨大なデータ数があれば別だと思うが。
rating_cnntrainer.py
上記のスクリプトで処理していることについて
| 項目 | 説明 |
| 画像入力 | CNNで64×64の画像から特徴を抽出 |
| 数値特徴量入力 | .npyファイルから読み込まれた錆特徴量(以下の表に記載) |
| ハイブリッド構造 | CNN特徴と手作り特徴を Concatenateで融合 |
| モデルバージョン | 3種類のCNN構造を用意したアンサンブル 学習 |
| 予測 | 3モデルの出力平均で最終スコアを判定 1〜5の評点に分類して保存 |
| 錆特徴量名 | 内容説明 | 特徴量例 |
| rust_ratio | 錆の占有面積(全体に対する割合) | 平均輝度、標準偏差、2値化による錆割合 |
| num_blobs | 錆のかたまり数(connected components) | 形状(個数) |
| np.mean(gray) | グレースケールの平均(明るさ) | GLCM(テクスチャ) コントラスト・相関・エネルギー・同質性 |
| np.std(gray) | グレースケールの標準偏差(濃淡の変動) | GLCM(テクスチャ) コントラスト・相関・エネルギー・同質性 |
| np.mean(sobel_edges) | エッジ強度(輪郭の激しさ) | Sobelエッジの平均 |
| area_diff | 最大面積 - 最小面積の錆領域の差 | 形状(面積差) |
ラベル付き画像 (947枚) を学習させてラベルを付けていない画像(665枚)を分類させた結果 Score1から順に10, 73, 538, 1, 43枚となった。Score4はたった1枚しか保存されておらずしかもその1枚が評点1相当の殆ど錆の画像であった。

CNN+binning.py
| 項目 | CNN分類 | CNN回帰 + binning |
| 出力層 | Dense(NUM_CLASSES. activation='softmax') | Dense(1)(活性化なし or ReLU) |
| 損失関数 | sparse_categorical_crossentropy | mean_squared_error (MSE) |
| 出力形式 | クラス確率(0〜1) | 連続値スカラー(例:3.72) |
| 評点の扱い | クラス分類(0〜4) | binning により 1〜5 に変換 |
今までのCNNは NUM_CLASSES(出力次元数 = 何クラスに分類するか) , softmax(確率的なベクトル出力をする際に用いられる関数) を用いて例えば錆の画像を評点1~5点で付けたい場合
model.add(Dense(5, activation='softmax')) → この場合NUM_CLASSES = 5
とスクリプトに入力すれば [0.1, 0.1, 0.7, 0.05, 0.05] のようなクラス(評点)ごとの確率(配列)で出力され、 argmax関数を用いてその配列の中で最大値のインデックスを返す。この配列の場合だと最大値は0.7になるので評点は3となる。このように錆画像の評点を1, 2, 3, 4, 5点と他クラスとの相対的な区別を学習するため人によって判断基準が異なる場合はこの分類方法はあまり適さない場合がある。一方でCNN回帰 + binningでは
model.add(Dense(1))
と入力すれば錆画像の評点は3.27点というように連続スカラー値で出力される。評点の決め方はラベル付きデータをCNNで学習し画像のパターン(色、濃淡、エッジ、形など)から点数を最適化。3.27という値は"学習データの中で、最も似ている例が3点と4点の中間"であることを意味する。これを binning 関数で1点刻みの評点に変換する。その変換方法は2.5点から3.5点の間に出力された数値は評点3というような感じで評点±0.5「評点のスケール」を意識して学習する。
loss='sparse_categorical_crossentropy'で正解クラスだけ1、それ以外0のone-hotラベル (異なるグループに分けられたデータを数値として表現するための手法) を元に確率分布を学習。
回帰の場合
loss='mean_squared_error'
で予測値 3.27 とラベル 3.0 との差 0.27 を最小化し「正解と近いスコアなら許容」という発想になる。
| def binning(score): |
| if score < 1.5: return 1 |
| elif score < 2.5: return 2 |
| elif score < 3.5: return 3 |
| elif score < 4.5: return 4 |
| else: return 5 |
学習時は回帰(MSE = 平均二乗誤差)で最適化されるが、推論後は binned 値に変換して accuracy_score (予測結果の正確さ) や confusion matrix (混同行列の可視化) を使って評価
from sklearn.metrics import accuracy_score, confusion_matrix
y_pred = model.predict(x_val).flatten() y_binned = [binning(p) for p in y_pred] acc = accuracy_score(y_val, y_binned)
CNN Backbone
┌───────────┐
│ Conv2D → Pool → ...│
└─────┬─────┘
▼
┌───────────┐
│ Flatten → Dense() │
└─────┬─────┘
▼
分類モデル 回帰モデル
┌─────────┐ ┌─────┐
│ Dense(5, softmax)│ │ Dense(1) │
└─────────┘ └─────┘
↓ ↓
argmax float値 → binning → int
これまでの結果から錆画像を識別するのはCNN回帰 + binning が精度の観点から1番可能性がありそうなので現段階ではこのモデルを軸に画像分類を進めていく。行き詰まってしまう, これよりももっと優れたモデルが見つかれば乗り換える可能性あり。
現時点(6/12現在)で使用している錆画像フォルダーとPythonスクリプト

回帰スコアから評点の分類を行っていた。スクリプトのデフォルトでは回帰スコア1.00〜1.50までを評点1, 1.51〜2.50までを評点2, 2.51〜3.50までを評点3, 3.51〜4.50までを評点4, 4.51〜5.00までを評点5としていたが、それでは上手いこと分類ができなかったので目視で錆画像を見ながら0.01点単位で評点の範囲を決めていた。その結果以下の表のように評点の分類を行なうこととした。またCNNの層を厚くしても精度は変わらないことが分かった。
| 評点 | 回帰スコア |
| 1 | 2.30点以下 |
| 2 | 2.31点以上3.00点以下 |
| 3 | 3.01点以上3.40点以下 |
| 4 | 3.41点以上3.64点以下 |
| 5 | 3.65点以上 |
以下回帰スコア別に保存された錆画像を貼っておく













































CNN+binning3.py
CNN+binning.py内のアンサンブル学習についての変更点(CNN+binning3.pyについて)
def create_model(version): #モデルを作成する関数の定義。引数 version によって使用するベースモデル(CNN)が変わる。
input_img = Input(shape=(*IMAGE_SIZE, 3)) #入力層の定義 IMAGE_SIZE は画像サイズ(例:224×224)を意味し、3 はRGB画像を意味する。
if version == 0: # EfficientNetV2S #version == 0 のとき軽量・高精度な EfficientNetV2S をベースに採用。
base = EfficientNetV2S(include_top=False, weights="imagenet", input_tensor=input_img) #include_top=False → 最終の分類層は除外。
#weights="imagenet" → ImageNetで事前学習された重みを使用。
#input_tensor=input_img → 上で定義した入力をモデルに接続。
elif version == 1: #version == 1 のとき DenseNet121 をベースに採用。
base = DenseNet121(include_top=False, weights="imagenet", input_tensor=input_img)
elif version == 2: #version == 2 のとき MobileNetV3Large をベースに採用。
base = MobileNetV3Large(include_top=False, weights="imagenet", input_tensor=input_img)
base.trainable = False #転移学習の初期段階ではベースモデルの重みを凍結(学習しない)。
x = base.output #ベースモデルの出力を取り出す(特徴マップ)。
x = layers.GlobalAveragePooling2D()(x) #2次元の特徴マップから平均値を取って1次元に圧縮。Flattenより計算効率が良く過学習を起こしにくい。
x = layers.Dense(512, activation='relu')(x) #512ユニットの全結合層。非線形変換(ReLU)で特徴を抽出。
x = layers.BatchNormalization()(x) #バッチごとに入力を標準化し学習安定化(精度や速度向上)。
x = layers.Dropout(0.5)(x) #ニューロンを50%の確率で無効化し、過学習を防ぐ。
x = layers.Dense(256, activation='relu')(x) #次の中間層 ユニット数を減らしながら段階的に抽象化しDropout率は少し下げている。
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.3)(x)
x = layers.Dense(128, activation='relu')(x) #より小さな次元にして最終出力に近づける。Dropoutは軽めにして出力を安定させる。
x = layers.Dropout(0.2)(x)
output = layers.Dense(1)(x) #出力層:1つの連続値(回帰値)を出力し評点を推定する回帰タスクに対応。
model = Model(inputs=input_img, outputs=output) #全てをまとめて Keras の Model として定義。
model.compile(optimizer='adam', loss=custom_penalizing_loss, metrics=['mae']) #Adam最適化を使用(自動調整が得意)。
#損失関数は custom_penalizing_loss(大きな誤差を強くペナルティ)。
#評価指標として mae(平均絶対誤差) も計算。
return model #構築したモデルを呼び出し元へ返す。
明日やること
CNN+binning2.py と CNN+binning3.py の比較
| 諸条件 | CNN+binning2.py | CNN+binning3.py |
| CNNモデル | 自作CNNモデル3パターン | EfficientNetV2S、DenseNet121、MobileNetV3Large の3種類 |
| 評点 | 回帰スコア |
| 1 | 0.00点以上2.30点未満 |
| 2 | 2.30点以上3.10点未満 |
| 3 | 3.10点以上3.40点未満 |
| 4 | 3.40点以上3.70点未満 |
| 5 | 3.70点以上5.00点未満 |
上記の条件でそれぞれ学習させると評点ごとに保存された枚数は以下の表に示す。
| 評点 | CNN+binning2.py | CNN+binning3.py |
| 1 | 24 | 13 |
| 2 | 110 | 119 |
| 3 | 54 | 123 |
| 4 | 59 | 146 |
| 5 | 418 | 264 |
評点が1, 2 の場合は判別に大きな差は見られなかったが、逆に評点3〜5は保存枚数に大きな差が見られCNN+binning2に関しては評点が3であろう錆画像が4や5に点在していたためスクリプトを改良する必要がありそうだ。CNN+binning3は評点5の画像が減ったものの評点3 ,4が混在してしまっている気がする。これらのグループは再度錆の大きさや面積に占める割合で判別するスクリプトを組み込む必要があるかもしれない。
CNN+binning3.pyに
を加えたところ回帰スコアが負の値や2桁になってしまったため、スコアの上振れ or 下振れするのを防ぐ目的で出力された回帰スコアにシグモイド関数をかけて0.00~5.00点以内になるよう調整した所スクリプトの構成が上手く行かない。(=エラーが頻発) また上手くいったとしても回帰スコアが全て同じ値になる。これはシグモイド関数の傾きを緩やかにすれば解決する可能性あり。来週には実行できる状態にさせたい。
CNN+binning4.py にUMAPを画像で出力することに加えて評点も出力されるようにした。ただ評点はシグモイド関数でつけているため出力された評点とどう組み合わせていくかを考えている必要があり、現在模索中。
CNN+binning5.py
CNN+binning5.pyの内容
EfficientNetV2S / DenseNet121 / MobileNetV3Large の3つの深層学習モデルを活用したアンサンブル学習を実装し、出力は 回帰スコア(0~5.0)+ Sigmoid関数 + binning処理(1〜5点に丸める) により、評点分類を実現。
画像からのCNN出力に加え、以下の 数値特徴量(4種類)を自動抽出してモデルに結合した。CNNベクトルと数値特徴をConcatenate層で結合し、Dense層により回帰スコアを出力。
-錆面積割合(rust_ratio) -粒径(平均・最大) -Sobelエッジ量 -錆の個数
特徴量(粒径, Sobel量など)に基づき評点を補正するためのしきい値を自動探索。評価指標 (accuracy_score) を最大化するように調整。
今まではCNNで評点付き錆画像を学習させた後、判別させたい錆画像の回帰スコアを出力し評点を決めていた。
例) 錆画像の回帰スコアが3.45点であり、評点と回帰スコアの対応が上記に示した表の通りであったとすると錆画像の評点は4となる
例を読んで理解できただろうか。今回はこの判別方法を行った後に画像の錆の数, 大きさ, 面積割合の特徴量(自動的に最適値を探すようにしている)を読み取って最終的な評点を決めるスクリプトを付け加えた。さらにシグモイド関数 パラメータを組み込むことで回帰スコアが0.00〜5.00の間になるよう調節できる。
ただUMAPでの分類はそれなりであるものの評点ごとに保存されている画像の枚数を確認すると評点1から順に 121, 168, 129, 1, 246枚となっており特に評点1と4が極端な枚数になっている。保存されている枚数が極端であるということは評点の付き方または特徴量の付け方に問題があるということなので明日以降に確認してみる。

ちなみにUMAPの理想は同じ色の点が密集しているのが理想である。点が固まっているところに複数色混在しているのは良くない。
評点を1.0~5.0点の間に変換する方法として シグモイド関数, 線形変換, 活性化関数がある。
1, シグモイド関数(+スケーリング) シグモイド関数 sigmoid(x) = 1 / (1 + e^(-x)) は、出力を [0,1] の間に制限する関数であり、それに4を掛けて1を加えれば(スケーリング)評点を1.0~5.0点の間に変換できる。
・実装方法 output = Dense(1, activation='sigmoid')(x) # → [0.0, 1.0] (シグモイド変換) output = Lambda(lambda z: 1.0 + 4.0 * z)(raw_output) # → [1.0, 5.0] (スケーリング) ※PCやバージョンによっては "Lambda" 関数がインストールされておらずエラーが出てしまう可能性がある。以下はLambdaを使わずに書いたスクリプト SIGMOID_SCALE = 5.0 # 出力を0〜5にスケーリング SIGMOID_K = 1 # 傾き係数(大きくするとS字が急) SIGMOID_X0 = 0 # 切片(出力の中心) -------------------------------------------------------------------------------------------------- output = layers.Dense(1)(x) output = ScaledSigmoid(SIGMOID_SCALE, SIGMOID_K, SIGMOID_X0)(x)
メリットとして上記のスクリプトを組み込むだけで1.0~5.0点の間に変換が可能であること (ワンライナー) 、出力が滑らか・連続的であるため学習しやすい事が挙げられる。デメリットは非線形変換のため中央(関数の変曲点=評点3.0付近)に予測が集中しやすく極端なスコア(1点や5点)が出力されにくくなることで分布が歪む可能性がある。また出力分布のコントロールが難しい (傾きや切片を任意で設定できるようなスクリプトを組むのはいいが自身で最適な値を見つけることは困難) 。
2, 線形変換(+出力範囲制限) 出力層は線形のまま Dense(1) を用いて範囲外の値(~1.0, 5.0~)をあとから切り落とす方法。例えば負の値や5.0を超えるような点が出力されてしまった場合前者は1.0に後者は5.0に丸められる。
・実装方法
output = layers.Dense(1)(x) output = layers.Lambda(lambda z: tf.clip_by_value(z, 1.0, 5.0))(output) ※Lambdaを実装しない場合(一例)
# === ClipLayer の定義 ===
@register_keras_serializable()
class ClipLayer(Layer):
def __init__(self, min_val=1.0, max_val=5.0, **kwargs):
super().__init__(**kwargs)
self.min_val = min_val
self.max_val = max_val
def call(self, inputs):
return tf.clip_by_value(inputs, self.min_val, self.max_val)
def get_config(self):
config = super().get_config()
config.update({
'min_val': self.min_val,
'max_val': self.max_val
})
return config
---------------------------------------------------------------------------------------------------------
output = layers.Dense(1)(x)
output = ClipLayer()(output)
メリットとしてシグモイド関数と同様に実装が簡単であり、ネットワーク出力の自由度が高く極端なスコアにも対応しやすいうえ線形なので分布の偏りが出にくい。デメリットとして範囲外に出た値はclip_by_valueによって強制的に最小or最大点に丸められることで、例えばある錆画像を学習結果をもとに判別した結果6.0と出力されたとき5.0に丸められてしまう。しかし機械学習モデルの予測値と実際の正解値との誤差を数値化する損失関数は "5.0" で計算されるため、「6.0と5.0の差」の情報を勾配として受け取ることで学習が進まないことがある。範囲外に出た値は学習に使わないことも出来るが極端な錆画像を学習する場合はどうなるだろうか。
3, 活性化関数 [tanh(x)] ( + スケーリング) シグモイド関数と異なる箇所は用いる関数のみで、活性化関数 tanh(x) は、出力を [-1, 1] の間に制限する関数であり、それに2を掛けて3を加えれば(スケーリング)評点を1.0~5.0点の間に変換できる。
・実装方法 output = Dense(1, activation='tanh')(x) # → [-1.0, 1.0] (シグモイド変換) output = Lambda(lambda z: 3.0 + 2.0 * z)(raw_output) # → [1.0, 5.0] (スケーリング) ※PCやバージョンによっては "Lambda" 関数がインストールされておらずエラーが出てしまう可能性がある。
メリットとして出力が中央(3.0)に対して対称でありシグモイド関数よりも中心から離れた値を出力しやすい(評点が1や5の場合でも分かりやすい)。デメリットとしてこれはシグモイドにも同じことが言えるがあまりにも極端すぎるものは出力の変化が鈍くなり学習が止まりやすい。
これらをまとめると
| 方法 | 評点の保証 | 出力の自由度 | 実装難易度 | 学習安定性 | おすすめ度 |
| 1. Sigmoid + スケーリング | ◎ 常に1~5 | △ 中央に寄る | ◎ 簡単 | ◎ 高い | 4 |
| 2. Clipによる制限 | ◯ 制限あり | ◎ 高い | ◎ 簡単 | △ 勾配停止あり | 2 |
| 3. Tanh + スケーリング | ◎ 常に1~5 | ◯ 対称性あり | ◯ 普通 | ◯ 中央寄り | 3 |
| 制限なし(今まで) | × 保証なし | ◎ 最大自由度 | ◎ 簡単 | × 不安定 | 1 |
どれも課題があるもののその中で学習安定性を重視したいと考えてシグモイド関数で評点を出している。ただ線形変換で評点を出して1.0~5.0に収まらなかった画像は学習に使わないというスクリプトも実装してみて精度とかを見てみる。
これから5つのアンサンブル学習(計15のCNNモデル)で精度・時間の比較を行っていく。学習条件(学習させる層, 学習回数など)は統一してある スクリプト(binning+CNN6.py)参照。
画像から評点を出すまでの流れ
1. 前処理・画像とスコアの準備
2. モデル構築・学習
3. 評点の予測
4. モデル評価・可視化
結果





5タイプのCNNモデルの結果
| パターン | 分類精度 | 分離度 | 安定性 | 処理速度 | コメント |
| A | ◎ | ◎ | ◎ | ○ | 実用・研究の両面でバランス型 安定+高精度 |
| B | △ | △ | △ | ◎ | 軽量だが精度不足 軽量で高速な実験をしたい |
| C | ◎ | ○ | ◎ | △ | 深層学習として高性能、やや重い 安定+高精度 |
| D | ○ | ○ | △ | ○ | 特徴は良いが評点にはやや曖昧さ |
| E | ◎ | ◎ | ◎ | △ | 最強構成、実装コスト高め 最大性能を目指す |
学習時間, 精度の面から元々行っていた CNN+binning3.py を改良して判別させたほうが良いという結論に至った。評点の変換についてこれからは評点に関数を掛けて1.0〜5.0点に全画像を収めるのではなくこの範囲に評点が収まらなかった画像は学習の対象外&結果を出力・保存しないこととした。
来週までにやること
Pythonスクリプトに 平均絶対誤差 と 混同行列の可視化 を追加した。⇒ CNN+binning3-UMAP.py
平均絶対誤差 MAE は1枚毎に予測値と正解値のズレの大きさを表し、例えば3枚の錆画像A, B, Cがありそれぞれ評点が3点, 5点, 2点であったとする。ラベル付されていない画像を学習した結果をもとにA, B, Cに再度評点(予測・回帰スコア)を付けてそれぞれ2.8, 4.3, 4.0 だった場合誤差は0.2, 0.7, 2.0 となる。MAEは0.3以内に収まれば正確な部類に入るのだが今回のMAEはおよそ0.967であるため正確性に欠ける結果となってしまった。混同行列は判別精度をを可視化するために導入した。
CNN+binning3-UMAP.pyで学習させてみた
| -項目- | -条件- |
| 評点を付ける画像サイズ(Fuji2) | 334×334ピクセル |
| 使用するCNNモデル | EfficientNetV2S / DenseNet121 / MobileNetV3Large |
| 全結合層 | 6層 |
| Dropout関数の実装 | あり |
| 活性化関数 | なし(出力された予測・回帰スコアをbinningスコアに変換) |
| 学習中に精度が良くならない状態が続いたら学習をやめるエポック数 | 10回(10回学習して改善されない場合は終了) |
| エポック数(学習する最大の回数) | 50回 |
※binningスコアと予測・回帰スコアの違いについて
# === binning: 予測・回帰スコア → 評点1〜5 ===
def binning(score):
if score < 2.00: return 1 #予測・回帰スコアが2.00点未満の場合は評点が1と出力
elif score < 2.50: return 2 #予測・回帰スコアが2.00点以上2.50点未満の場合は評点が2と出力
elif score < 3.00: return 3 #予測・回帰スコアが2.50点以上3.00点未満の場合は評点が3と出力
elif score < 3.50: return 4 #予測・回帰スコアが3.00点以上3.50点未満の場合は評点が4と出力
else: return 5 #予測・回帰スコアが3.50点以上の場合は評点が5と出力
上記の条件に当てはめると予測・回帰スコアは以下のように変換することが出来る
| 予測・回帰スコア | → binningスコア |
| 1.96 | → 1 |
| 2.23 | → 2 |
| 2.86 | → 3 |
| 3.48 | → 4 |
| 4.01 | → 5 |
CNN+binning5.py上記のスクリプトで行われていること
例)📂 1_001.jpg → 回帰: 2.62 → 補正後: 2.52 → 評点: 2 | 錆割合: 0.253, 錆数: 375, 最大錆: 470
📂 1_002.jpg → 回帰: 3.14 → 補正後: 3.14 → 評点: 3 | 錆割合: 0.145, 錆数: 807, 最大錆: 158
📂 1_003.jpg → 回帰: 2.71 → 補正後: 2.71 → 評点: 3 | 錆割合: 0.237, 錆数: 611, 最大錆: 1188
📂 1_004.jpg → 回帰: 3.37 → 補正後: 3.67 → 評点: 4 | 錆割合: 0.086, 錆数: 728, 最大錆: 106
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜 省略 〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
📂 4_094.jpg → 回帰: 2.58 → 補正後: 2.48 → 評点: 2 | 錆割合: 0.253, 錆数: 410, 最大錆: 638
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜 省略 〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
平均絶対誤差:0.11544688538164781(0.3を下回っていれば精度的に"良")
# 特徴量によるスコア補正関数(抜粋)
def adjust_score_by_features(score, rust_ratio, rust_count, max_blob_area):
correction = 0.0
#錆面積割合
if rust_ratio >= 0.70:
correction -= 0.4 #錆面積割合が0.7(70%)を超えていたら回帰スコアから0.4点マイナスする。
#elif 0.50<= rust_ratio < 0.70: #評点の結果に応じてこのように範囲, 値を自由に設定可能。
# correction -= 0.3
elif rust_ratio < 0.10:
correction += 0.2
#錆の数
if rust_count > 800:
correction -= 0.1
〜〜〜〜〜〜 省略 〜〜〜〜〜〜
#最大錆サイズ
if max_blob_area >= 10000:
correction -= 0.3
〜〜〜〜〜〜 省略 〜〜〜〜〜〜
return score + correction ⇒
⇒

CNNによる回帰スコアに対して画像特徴量(錆割合、錆数、最大錆サイズなど)を加味することで、最終的な評点結果にどのような影響が現れるのかを検証した。そのために2種類のPythonスクリプト(CNN+binning4.py、CNN+binning5.py)を使い分けて比較を行った。ちなみに2つのスクリプトの違いは学習と判別に特徴量を入れているかどうかである。
以下に結果を示す







| グラフの色 | 学習に用いたpython | 評点算出の際に用いたpython | 特徴量 |
| 青 | CNN+binning4.py | CNN+binning5.py | 0.1783 |
| 朱 | CNN+binning4.py | CNN+binning4.py | 0.1756 |
| 緑 | CNN+binning5.py | CNN+binning5.py | 0.1496 |
| 黃 | CNN+binning5.py | CNN+binning4.py | 0.1510 |
CNN+binning6.py
binning5.pyには実装しなかった重回帰分析がメインとなる。今までは各特徴量(錆割合・面積比・錆の数)の大きさに応じて回帰スコアから点数を加減していたが、重回帰を入れることで .pkl ファイルと .csv ファイルから特徴量の重みを自動で最適化してもらうようにした。しかしMAEがCNN+binning5.pyより大きくなってしまっているため出来が良くないかそれともまだ改善の余地があるのだろうか。
| 回 | 錆面積範囲 | 錆数 | 最大錆サイズ | MAE | 評点別画像分布(左側から順に評点1、2 …) |
| 1 | 定義しない | 定義しない | 定義しない | 0.129 | 13-133-420-78-21 |
| 2 | 0.5以上:-0.4 0.35以上0.5未満:-0.15 0.1以下:+0.15 | 800以上:+0.1 | 10000以上:-0.3 250未満:+0.1 | 0.135 | 22-124-374-118-27 |
| 3 | 0.5以上:-0.4 0.35以上0.5未満:-0.15 0.05以下:+0.15 | 550以下:+0.2 | 10000以上:-0.2 5000以上10000未満:-0.1 50以上150未満:+0.1 50未満:+0.2 | 0.133 | 17-72-432-107-37 |
| 4 | 2と変化なし | 削除(定義しない) | 2と変化なし | 0.127 | 22-126-406-85-26 |
| 5 | 0.5以上:-0.4 0.33以上0.5未満:-0.15 0.05以上0.1未満:+0.1 0.05未満:+0.2 | 削除(定義しない) | 10000以上:-0.3 5000以上10000未満:-0.2 50以上200未満:+0.1 50未満:+0.2 | 0.127 | 27-121-406-99-32 |
| 6 | 0.6以上:-0.5 0.45以上0.6未満:-0.3 0.25以上0.45未満:-0.1 0.05未満:+0.3 | 1000以上:-0.2 500以上1000未満:-0.1 100以下:+0.1 | 15000以上:-0.4 8000以上15000未満:-0.2 100以下:+0.2 | 0.124 | 24-139-397-71-33 |
| 7(重回帰) | ーーー | ーーー | ーーー | 0.126 | 13-125-375-115-27 |
特徴量に応じて回帰スコアから加減点を行うことは、定義しないときと比較してMAEは小さくなっているものの正確性は僅か1%ほどしか変わらず必ずしも特徴量を考慮する必要性は無いように思える。結局は学習させる画像が少ないのかはたまたラベル付けが下手なのか色々要因は考えられそうだが、どちらかと言えばラベル付き画像が少ない方に原因があってほしい。とりあえずデータを4倍とかに増やして後日学習させたい。
データ数を増やすのはもう少し時間がかかりそう。重回帰で学習させてみたところ重回帰なしの場合と比較してMAEにそこまで違いが見られなかったので
を1つのスクリプトにまとめたものをこれから1周間で作成できればと思っている。現地調査で得られる錆画像の学習を考慮して重回帰を軸にスクリプト作成をこれからは行っていきそうだ。
機械学習についてはやはり学習元となるセロハン試験で採取されたラベル付き錆のモノクロ画像が絶対数足りないためこの新たなデータが待たれる。現在はラベル付き画像を約10,000枚に増やして学習をさせているがMAEは変化しない。

上記の画像(混同行列)は10,000枚近くあるラベル付きの画像の中から20%にあたる2,000枚弱をテスト用データとして残り80%の画像を3つの学習モデルで学習、その結果を .keras ファイルで保存して正確に判別できるかどうか試したものである。縦軸 True label が実際の評点 横軸の Predicted label が .keras ファイルをもとに予測した評点をそれぞれ表しており、左上から右下への対角線上が青くなっているほど正確に予測できたと言えるのだがご覧の通り対角線以外の部分が青くなっている。各評点ごとの判別率は評点1から順に 81%, 85%, 100%(に限りなく近い), 34%, 84% となっており、特に評点4の精度が低くその原因として
結果

生成された画像が少ないが評点4の正答率が大幅に向上した。(58 / 185 → 57 / 58)他の評点においてもラベル付き画像を10枚に増やして学習を行うことにする。評点5は元々の画像が少ないので10枚にする必要はないかも

画像を水増ししすぎてしまったのか綺麗な対角線を描けなかった。上手く言ったときは1枚あたり60枚水増し、今回は1枚あたり3倍の約180枚水増し 過学習を引き起こしたことで思った結果が得られなかったのか明日検証してみる。
| モデルNo. | 水増し画像枚数 | 水平・鉛直方向への移動 | 学習回数 | バッチサイズ |
| 1 | 50 | あり(水平・垂直ともに最大10%移動 他のモデルも同様) | 30回 | 32枚 |
| 2 | 50 | なし | 30回 | 32枚 |
| 3 | 50 | あり | 50回 | 32枚 |
| 4 | 50 | なし | 50回 | 32枚 |
| 5 | 50 | あり | 30回 | 64枚 |
| 6 | 50 | なし | 30回 | 64枚 |
| 7 | 50 | あり | 50回 | 64枚 |
| 8 | 50 | なし | 50回 | 64枚 |
| 9 | 100 | あり | 30回 | 32枚 |
| 10 | 100 | なし | 30回 | 32枚 |
| 11 | 100 | あり | 50回 | 32枚 |
| 12 | 100 | なし | 50回 | 32枚 |
| 13 | 100 | あり | 30回 | 64枚 |
| 14 | 100 | なし | 30回 | 64枚 |
| 15 | 100 | あり | 50回 | 64枚 |
| 16 | 100 | なし | 50回 | 64枚 |
| 17 | 150 | あり | 30回 | 32枚 |
| 18 | 150 | なし | 30回 | 32枚 |
| 19 | 150 | あり | 50回 | 32枚 |
| 20 | 150 | なし | 50回 | 32枚 |
| 21 | 150 | あり | 30回 | 64枚 |
| 22 | 150 | なし | 30回 | 64枚 |
| 23 | 150 | あり | 50回 | 64枚 |
| 24 | 150 | なし | 50回 | 64枚 |
| 条件内容 | 条件 |
| ランダム回転(画像を 最大 ±(記入された数字)° の範囲でランダム回転) | 最大±15°回転 |
| 画像を反転させるか | ON |
| 画像の明るさ変更(明るさをA倍(暗く)〜B倍(明るく) の範囲でランダム変更) | 0.8〜1.2倍に設定 |
| 使用するCNNモデル | EfficientNetV2S、DenseNet121、MobileNetV3Large |
| モデルNo. | MAE |
| 1 | 0.196729463582136 |
| 2 | 0.243831214856128 |
| 3 | 0.195313368524824 |
| 4 | 0.144703118168578 |
| 5 | 0.205965055494892 |
| 6 | 0.289931784357343 |
| 7 | 0.17892047945334 |
| 8 | 0.230305907920915 |
| 9 | 0.126362581399022 |
| 10 | 0.0984963168903273 |
| 11 | 0.132567102081922 |
| 12 | 0.0933165281402821 |
| 13 | 0.162534093126959 |
| 14 | 0.183336140306628 |
| 15 | 0.173845792789849 |
| 16 | 0.0904155796279713 |
| 17 | 0.108065831782867 |
| 18 | 0.095051087976313 |
| 19 | 0.104002416782639 |
| 20 | 0.0796793378534771 |
| 21 | 0.204868344141513 |
| 22 | 0.206347949407539 |
| 23 | 0.092119121267682 |
| 24 | 0.256283822351573 |
| モデルNo. | 水増し画像枚数 | 水平・鉛直方向への移動 | 学習回数 | バッチサイズ | MAE |
| 20 | 150 | なし | 50回 | 32枚 | 0.0796793378534771 |
| 16 | 100 | なし | 50回 | 64枚 | 0.0904155796279713 |
| 23 | 150 | あり | 50回 | 64枚 | 0.092119121267682 |
| 12 | 100 | なし | 50回 | 32枚 | 0.0933165281402821 |
| 18 | 150 | なし | 30回 | 32枚 | 0.095051087976313 |
| 10 | 100 | なし | 30回 | 32枚 | 0.0984963168903273 |
| 19 | 150 | あり | 50回 | 32枚 | 0.104002416782639 |
| 17 | 150 | あり | 30回 | 32枚 | 0.108065831782867 |
上記の結果より学習回数(の上限)は50回, 画像の水増し枚数は150枚/1枚あたりで学習を行ったほうがMAEは良くなることが分かった。一方で画像の加工についてだが移動に関しては動かさないほうがより良い結果に結びつくのではないかと推測し、バッチサイズの大きさはそこまで学習に影響を及ぼさない事が収穫か。次回は学習回数, バッチサイズを統一して1枚あたりの水増し枚数, 画像加工に関するパラメーターを弄りながらMAEの変化を見ていくことにする。
CNN+binning5-1.py CNN+binning7.py
今までは画像の水増しと学習を別々に行っていた(始めにMMLI.pyなどでラベル付きの画像を水増しした後CNN+binning5.py等で学習をさせていた)が、CNN+binning5-1.pyより1つのモデルに対する画像生成・学習を一括で行えるようにした。またCNN+binning7.pyは5-1の拡張版のようなもので画像を拡張するにあたり回転の大きさ, 明るさ, 画像の水増し枚数等の要素や学習方法(学習回数, バッチサイズ)を任意で設定可能にした且つ全通りの学習を一度に行えるようになった。つまり学習が1回完了するごとにMAEや行列を確認する必要がなくなり複数の学習モデルを比較できるようになったわけである。
CNN+binning5-1.py で出力された .keras ファイル(MAEは0.07)を CNN+binning5.py に適応したところMAEが0.14になった。既存の .keras がある状態でラベル付き画像を学習することはないので根本的な原因は双方の学習方法にありそうだがどうだろうか。来週には調べられたらと思っている。
今現在の学習方法を以下に示す
1, オリジナル画像の読み込み 2, 画像をアスペクト比を維持しながらリサイズ・パディング 3, 回転・明るさ調整・シフトなどを加えた画像を複数枚生成してデータを水増し 4, 水増し済み画像の読み込んでラベル(スコア)を抽出 5, 学習用と検証用にそれぞれ総画像枚数 8:2 に分割 6, EfficientNetV2S / DenseNet121 / MobileNetV3Large の 3種類をベースにした回帰モデルを作成 7, モデル( .keras ファイル)が保存済みなら再利用なければ学習して生成 8, 検証用データの結果をもとにMAE(平均絶対誤差), 混同行列(binning で1〜5に丸めた結果を利用), UMAP を保存 9, ラベルがついていない画像を読み込んで推論値(回帰スコア)を算出し、錆割合・錆の数・最大錆サイズ等の特徴量を抽出し予め設定しておいた補正値を加算 10, 各画像ごとの推論結果, MAE, データ数, タイムスタンプ等を csv ファイルとして保存
現在実装している補正関数は以下の通り ペナルティ関数と補正関数の2種類が実装されている
@register_keras_serializable()
def custom_penalizing_loss(y_true, y_pred): #pred = prediction(予測)
diff = tf.abs(y_true - y_pred)
return tf.reduce_mean(tf.square(diff) * (1.0 + tf.pow(diff, 1.5)))
誤差(diff) = |y_true - y_pred| を二乗しつつ(1 + diff^1.5) で大きな誤差を強くペナルティする → 外れ値や大きな誤差を強く抑える
def adjust_score_by_features(score, rust_ratio, rust_count, max_blob_area):
correction = 0.0 #リセット
# 錆面積割合
if rust_ratio >= 0.60:
correction -= 0.5
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
# 錆の数
if rust_count >= 1000:
correction -= 0.2
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
# 最大錆サイズ
if max_blob_area >= 15000:
〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜
return score + correction #補正前評点+補正関数
錆割合・錆の数・最大錆サイズに基づいてスコアを ±0.1〜0.5 程度補正し、小さな錆 → 加点、大きな錆 → 減点というような感じで付けている。
現在使用しているモデル(CNN+binning7.py)と以前使用していたモデル(CNN+binning5.py)の各スコア・評点の比較(各特徴量はどちらも同じ値をとっていたため省略) 画像はどちらもランダムに15枚抽出した同じものを使用した。



CNN+binning.pyのVerが上がるごとに学習方法も変化してくるので前モデルと現モデルの比較を行ってみた。全画像を比較していないので断言は出来ないが、1番誤差があると考えられる補正後スコアの2番は0.2ポイントほどでありどの要素もそこまで大きく乖離している部分は見受けられなかった。
昨日の夜に学習が強制終了されていた。どうやら学習時にメモリを消費しすぎて落ちてしまうらしい。そこで少しでも使用するメモリを抑えるため学習時に numpy 配列をそのまま渡していたのをやめて tf.data.Dataset を使用するように変更し、学習ごとにどのような条件で行ったのかがわかるように出力されるログの部分に ”水増し枚数”, ”回転角度”, ”明るさ”, ”縦移動”, ”横移動”, ”エポック数”の各要素を記載するようにした。今現在組み合わせをかなり減らして学習を行わせているのでなんとか学習を終えてほしい。
また強制終了していた。学習の組み合わせを2パターンにして回してみるがこれで回らなかったらスクリプト全体を見直す必要がありそうだ。主な原因としてバッチサイズが大きすぎる(現在32で学習させている=1グループあたり何枚にするかを決める)ことによるGPUメモリの使い切りが考えられる。バッチサイズを小さくすることでトータルで学習に時間がかかってしまうが、一度に使用するメモリを抑えることができるのでバッチサイズを16や8にして学習させてみたい。だが今までの学習ではバッチサイズを32で統一してきたので、より小さくすることで結果に影響が出ないのかを見ておく必要がありそうだ。
CNN+binning7-1.py
スクリプトの簡略化と一度に複数回学習を行えるようにした機能を追加したところ最後まで学習が行われない問題が発生したので(CNN+binning7.py)、簡略化を断念し各学習ごとにパラーメータを記載するようにした。試しに2通りの学習モデルを実装して回した。
エポック数を1にして回してみたところ終わったので構造に問題はなさそう。学習中にモニターの動作が遅くなるようなことはなし。
現在全64パターンを学習中 画面が固まるようなことなく無事に学習が続いている。31日から始めてまる2日ほど経過しただろうか 27パターン目まで学習完了しているので単純計算でもう2, 3日は掛かりそうだ。現在精度の良いモデルを見つけるにあたってMAEという指標を用いて探しているのだが、どうやら他にも混同行列, Macro F1, 単純精度-Accuracyも精度の良し悪しに関して判断材料となりそうだ。
39パターン目の学習が終了した時点で強制終了となっていた。ターミナル上で学習が1回終わる毎にPCに積んであるメモリの何%を使用しているか確認できるようにしたことに加えてメモリの開放を実装した。もし開放していても使用メモリが徐々に上がっていたらまた何か対策を考えなければ。とりあえず今(9:30 a.m.)は全16パターンの学習を始めたところで上手く動くか様子を見ていくつもり 明日の朝来たときには終わっていてほしい。
中間発表に向けて準備を進めているが現地調査の結果次第で書く内容を修正する必要性があるので、概要に関しては背景〜方法までを書き上げたもののスライドに関しては何もやっていない。とりあえず8日までにできれば終われせておきたいことリストを以下に示しておく。
・各CNNモデルごと(単体)で学習させた結果とアンサンブル学習の結果比較
・概要の見直し
・概要を書き上げた部分までに該当するスライド作成
1枚あたりの生成枚数を200枚固定, 画像の加工処理範囲を変化させながら学習させてみたところ以下のような結果が得られた。
| 明るさ(通常は1.0以下だと暗、1.0以上だと明) | 縦の移動(百分率) | 横の移動(同左) | MAE | 正答率(百分率) | macrof1 |
| (0.8、1.2) | (-0.05、0.05) | (-0.05、0.05) | 0.123 | 0.841 | 0.793 |
| (0.8、1.2) | (-0.05、0.05) | (-0.1、0.1) | 0.124 | 0.824 | 0.755 |
| (0.8、1.2) | (-0.1、0.1) | (-0.05、0.05) | 0.131 | 0.818 | 0.753 |
| (0.8、1.2) | (-0.1、0.1) | (-0.1、0.1) | 0.128 | 0.815 | 0.762 |
| (0.7、1.3) | (-0.05、0.05) | (-0.05、0.05) | 0.134 | 0.818 | 0.773 |
| (0.7、1.3) | (-0.05、0.05) | (-0.1、0.1) | 0.133 | 0.814 | 0.759 |
| (0.7、1.3) | (-0.1、0.1) | (-0.05、0.05) | 0.126 | 0.816 | 0.769 |
| (0.7、1.3) | (-0.1、0.1) | (-0.1、0.1) | 0.134 | 0.817 | 0.786 |
結果として水増しする枚数を多くしたりパラメータをいじったりしても精度にはほどんど影響されないことが分かった。逆に学習は明るさに左右されないということもここから読み取れる。これは既存の錆画像を水増ししただけでは精度は向上しないと暗に示しているのではないかと思われ、明日, 明々後日の調査で得られる錆画像を学習に取り入れて結果に変化が出るか見る必要がありそうだ。ちなみに結果の上段から順に1, 3, 5, 7段目の混同行列の結果を貼り付けておく。大して結果が変わっていない以上各行列にも大きな変化は見当たらないが、どれも評点4の判別に苦戦しているようだった。(ラベル付き画像を増やせば改善されるかも)




各CNNモデル単体とアンサンブル学習の結果比較は9日の午後時点で進行中 今日中に終えられるのかは厳しいところ
| Model | Accuracy | MAE |
| EfficientNetV2S | 0.807 | 0.211 |
| DenseNet121 | 0.864 | 0.112 |
| MobileNetV3Large | 0.858 | 0.138 |
| Ensemble | 0.849 | 0.124 |
どのモデルも精度には申し分ないのだが、アンサンブルの結果が一番だと思っていた予想を裏切られた。他のモデルも試してみる必要があるか それともDenseNetだけで学習させる必要があるのか。
"DenseNet121", "InceptionResNetV2", "Xception" の3モデルとアンサンブルのMAE・正答率を比較したところ以下のような結果になった。
| Model | Accuracy | MAE |
| DenseNet121 | 0.863 | 0.109 |
| InceptionResNetV2 | 0.862 | 0.109 |
| Xception | 0.857 | 0.110 |
| Ensemble | 0.861 | 0.103 |




新CNNモデルの組み合わせでそれぞれ学習, アンサンブルを行ったところ以下のような混同行列が得られた。因みに水増し枚数は50枚で統一している。




画像の水増し枚数は50枚, 水増しの際に画像にする加工処理はなるべく弱めにすることが精度向上のコツなのだが正答率85%よりも上を目指すにはどうしたら良いか考える必要がある。
CNN+binning7-2.py
CNN+binning7-1.py に 誤差解析ツール(MAE, Accuracy, Macro-F1, クラス別MAE, ±1精度, 残差・誤差相関プロット)を組み込み、評価結果が保存されるようにした。現在アンサンブルの精度が伸び悩んだ原因を分析中で組み込んだ誤差解析ツールの結果待ち。
新旧の両モデルを学習させて結果の比較を行っている 新モデルの学習は完了し今日の夜ごろには旧モデルが終わる見込み
今月上旬に行った現地調査で採取した錆付きテープをスキャナーで線画・カラーの両方でスキャンして学習に取り入れた。年末の発表までに良い結果が得られればよいのだが、学習させてみて精度に影響を及ぼすか見てみる MAEが0.10を下回ればラベル付き画像を導入した甲斐があったといえるか。CNN+binning7-21.py をいじっていたら学習に水増しした画像にさらに水増しを行った画像で行っていることが発覚し、元画像から1回だけ水増しした画像たちで学習させたところMAEやF1スコアがとんでもなく悪化した。ただ収穫もあり、37万枚程学習させないと精度は良くならないことが分かった。
調査で採取した錆画像を取り入れたことでラベル付き画像が既存の枚数から2倍以上に増えた。水増しする枚数を変化させながら(元画像✕500, 1000, 1500, 2000, 3000枚)結果がどうなるかを見てみようと思う。以下に各枚数ごとの精度指標を載せておく。
| 精度指標 | 水増し500枚 | 水増し1000枚 | 水増し1500枚 | 水増し2000枚 | 水増し3000枚 |
| MAE(Ensemble) | 2.576 | 2.364 | 1.931 | 3.012 | 3.15 |
| 正答率 | 0.304 | 0.261 | 0.217 | 0.261 | 0.217 |
| F1スコア | 0.093 | 0.083 | 0.071 | 0.083 | 0.071 |
| 各評点ごとのMAE | 水増し500枚 | 水増し1000枚 | 水増し1500枚 | 水増し2000枚 | 水増し3000枚 |
| 評点1 | 1.573 | 1.183 | 0.647 | 1.364 | 1.594 |
| 評点2 | 2.352 | 2.111 | 1.683 | 2.496 | 2.589 |
| 評点3 | 2.516 | 2.456 | 1.985 | 3.244 | 3.399 |
| 評点4 | 3.302 | 3.211 | 2.691 | 4.090 | 4.057 |
| 評点5 | 4.003 | 3.531 | 3.263 | 4.658 | 4.537 |
元画像114枚から水増しを1回だけ行った結果、以前に言った通り精度が低下してしまった。114枚 → 約36万枚だと画像レパートリーが不十分なのか納得のいく結果が得られない。元々は水増しした画像をさらに水増しするとMAEが0.10あたりになる。今回の場合114枚 → 5700枚 → 約36万枚で増やすと上手くいく やはり元画像は6000枚はないと厳しいか。
学習が強制終了していたためもう一度回しているが、無事学習し終えるかどうかは五分五分といったところ
中間発表が終わってやること
import os # ファイルパスやフォルダ操作のための標準ライブラリ
import cv2 # 画像処理用ライブラリ(OpenCV)
import shutil # フォルダ削除やコピー操作に使用
import numpy as np # 数値計算ライブラリ(行列演算などに必須)
import seaborn as sns # グラフ描画を綺麗にするための補助ライブラリ
import tensorflow as tf # Deep Learning フレームワーク(Kerasを内包)
from PIL import Image # 画像の入出力・変換処理用
from tensorflow.keras import layers, models, Input, Model # Keras モデル構築系の基本構成要素
from tensorflow.keras.models import load_model # 保存済みモデルの読み込み用
from tensorflow.keras.layers import Layer # カスタムレイヤーを定義するために使用
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint # 学習制御用のコールバック
from sklearn.model_selection import train_test_split # 学習データと検証データを分割する関数
from sklearn.metrics import mean_squared_error, confusion_matrix, classification_report, mean_absolute_error # モデル評価のための関数群
from tensorflow.keras.applications import DenseNet121, InceptionResNetV2, Xception # 転移学習で利用するCNNモデル3種類の定義
import matplotlib.pyplot as plt # グラフや画像を描画するためのライブラリ
import pandas as pd # データフレーム操作ライブラリ(結果集計などで使用)
import psutil # メモリ使用量確認用ライブラリ
import datetime # 実験時間や日付の記録用
import gc # メモリ開放(ガーベジコレクション)を強制的に行う
# === 基本設定 ===
NUM_MODELS = 3 # アンサンブルに使用するモデルの数(今回は3種類のCNNモデルを使用)
TRAIN_FOLDER = "train_images" # 学習用に用いるデータを保存しておくフォルダ
TEST_FOLDER = "Fuji2" # 評価用データフォルダ
BASE_RESULTS_DIR = "results_patterns1-2" # 学習結果を保存するディレクトリ名
IMAGE_SIZE = (256, 256) # すべての画像を256×256にリサイズしてから学習を行う
USE_COLOR = False # False → 白黒で処理(True の場合はカラーで処理される)
MODEL_PATHS = [f"ensemble_model_{i+1}.keras" for i in range(NUM_MODELS)] # モデル保存用ファイル名(.keras ファイル)を自動生成
# === フォルダの削除・作成 ===
if os.path.exists(BASE_RESULTS_DIR): # 既に結果フォルダがある場合
shutil.rmtree(BASE_RESULTS_DIR) # そのフォルダを丸ごと削除して
print(f"既存のフォルダ '{BASE_RESULTS_DIR}' を削除しました。") # 削除完了を通知
os.makedirs(BASE_RESULTS_DIR, exist_ok=True) # 新しいフォルダを作成
print(f"新しいフォルダ '{BASE_RESULTS_DIR}' を作成しました。")
# === 学習パターンの定義 ===
patterns = [
{'name': 'pattern_1', 'epochs': 50, 'batch_size': 32, 'num_aug':40, 'rotation': (-100, 100), 'brightness': (0.7, 1.3), 'width_shift': (-0.5, 0.5), 'height_shift': (-0.5, 0.5)},
{'name': 'pattern_2', ...
]
#ここでパターンごとに各パラメータを設定する(name:学習結果を保存するディレクトリ名, epochs:学習回数, batch_size:バッチサイズ設定, num_aug:1枚の画像から水増しする枚数, rotation:回転角度(定義された数値内でランダム), brightness:明るさ(定義された数値内でランダム), width_shift:横移動(定義された数値内でランダム), height_shift:縦移動(定義された数値内でランダム))
# === 学習画像とスコアの読み込み関数 ===
def load_images_and_scores(folder):
images, scores = [], [] # 画像データとスコアを格納するリストを初期化
for fname in sorted(os.listdir(folder)): # 指定フォルダ内のファイルをソートして順に処理
if fname.endswith(".png") or fname.endswith(".jpg"): # 対象はPNGまたはJPEG画像
try:
score = float(fname[0]) # ファイル名の先頭文字(例:3_001.jpg → 3)をスコア(ラベル)として取得
score += np.random.uniform(-0.2, 0.2) # ±0.2 の乱数を加えて Soft Label 化(過学習防止)
if score < 0.00 or score > 5.50: # 学習をもとに出力されたスコアが0点以下または5.50点以上の場合はスキップし、結果に反映させない
print(f"⚠️ スコア範囲外: {fname} → {score:.2f} → スキップ")
continue
path = os.path.join(folder, fname) # ファイルパスを生成
img = Image.open(path).convert("RGB").resize(IMAGE_SIZE) # 画像をRGB化&256×256に統一
images.append(np.array(img) / 255.0) # ピクセル値を0〜1に正規化してリストに追加
scores.append(score) # スコアを追加
except Exception as e: # エラーが起きた場合に備えて例外処理
print(f"⚠️ 読み込み失敗: {fname}, 理由: {e}")
return np.array(images), np.array(scores) # Numpy配列として返す
# === カスタム損失関数 ===
@register_keras_serializable()
def custom_penalizing_loss(y_true, y_pred): # 予測値と正解値の差に基づく損失を定義
diff = tf.abs(y_true - y_pred) # 絶対誤差を計算
return tf.reduce_mean(tf.square(diff) * (1.0 + tf.pow(diff, 1.5))) # 誤差が大きいほどペナルティを強くする(差が大きいサンプルを重点的に修正)
# 通常のMSEよりも大誤差を強調し、外れ値を抑制する効果
# === CNNモデル構築関数 ===
def create_model(version):
input_img = Input(shape=(*IMAGE_SIZE, 3)) # 入力画像サイズを定義(256×256×3)
# CNNモデルごとに異なるベースアーキテクチャを使用
if version == 0:
base = DenseNet121(include_top=False, weights="imagenet", input_tensor=input_img) # DenseNet121を利用
elif version == 1:
base = InceptionResNetV2(include_top=False, weights="imagenet", input_tensor=input_img) # InceptionResNetV2を利用
elif version == 2:
base = Xception(include_top=False, weights="imagenet", input_tensor=input_img) # Xceptionを利用
base.trainable = False # 転移学習:ベースモデルの重みを固定して学習させない
# グローバルプーリングで特徴マップを1次元に圧縮
x = base.output
x = layers.GlobalAveragePooling2D()(x)
# 全結合層(Dense)を追加して非線形特徴を学習
for units, dr in [(2048, 0.5), (1024, 0.4), (512, 0.3), (256, 0.2), (128, 0.15), (64, 0.1)]:
x = layers.Dense(units, activation="relu")(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(dr)(x)
output = layers.Dense(1)(x)
#-----------------------展開すると-----------------------↓
x = layers.Dense(2048, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.5)(x) # 過学習防止
x = layers.Dense(1024, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.4)(x)
x = layers.Dense(512, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.3)(x)
x = layers.Dense(256, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.2)(x)
x = layers.Dense(128, activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.15)(x)
x = layers.Dense(64, activation='relu')(x)
x = layers.Dropout(0.1)(x)
output = layers.Dense(1)(x) # 最終出力は1次元の連続値(錆のスコア)
#---------------------------------------------------------------
model = Model(inputs=input_img, outputs=output) # モデルを構築
model.compile(optimizer='adam', loss=custom_penalizing_loss, metrics=['mae']) # 学習設定
return model # 完成したモデルを返す
# === 錆特徴量抽出関数 ===
def extract_features(image, use_color=False): # 錆の特徴量を抽出(面積・数・最大錆サイズなど)
gray = np.array(image.convert("L")) # 画像をグレースケールに変換
if use_color: #錆画像をカラーで学習させた場合
hsv = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2HSV) # HSV空間に変換(錆の色抽出用)
lower_rust = np.array([5, 50, 50]) # 錆の色の下限値(橙〜茶)
upper_rust = np.array([25, 255, 255]) # 錆の色の上限値
mask = cv2.inRange(hsv, lower_rust, upper_rust) # 錆領域のマスク生成
else: #錆画像を白黒で学習させた場合
_, mask = cv2.threshold(gray, 128, 255, cv2.THRESH_BINARY_INV) # 白黒画像の場合、128を閾値にして錆部分(暗い部分)を抽出
rust_ratio = np.sum(mask > 0) / mask.size # 錆が占める割合(面積比)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 輪郭を抽出(錆の個数などを把握)
rust_count = len(contours) # 錆の数
max_blob_area = max([cv2.contourArea(c) for c in contours], default=0) # 最大の錆面積
return rust_ratio, rust_count, max_blob_area # 錆割合・錆数・最大錆サイズを返す
# === CNNの回帰スコアに基づく補正関数 ===(今回は未使用)
def adjust_score_by_features(score, rust_ratio, rust_count, max_blob_area):
correction = 0.0 # 補正値の初期化
if score >= 4.5:
return score # 高スコア(重度錆)は補正しない
# 錆面積割合に基づく補正
if rust_ratio >= 0.60: # 錆の割合が60%以上だった時
correction -= 0.5 # 錆が非常に多い → 学習によって出力された評点から0.5点マイナス
elif 0.45 <= rust_ratio < 0.60:
correction -= 0.3
elif 0.25 <= rust_ratio < 0.45:
correction -= 0.1
elif rust_ratio < 0.05:
correction += 0.3 # 錆が少ない → 学習によって出力された評点から0.3点プラス
# 錆の個数による補正
if rust_count >= 1000: #錆の数が1000個以上の場合
correction -= 0.2 #学習によって出力された評点から0.2点マイナス
elif 500 <= rust_count < 1000:
correction -= 0.1
elif rust_count < 100:
correction += 0.1
# 最大錆サイズによる補正
if max_blob_area >= 15000: #最大錆の大きさが15000ピクセル以上の場合
correction -= 0.4 #学習によって出力された評点から0.4点マイナス
elif 8000 <= max_blob_area < 15000:
correction -= 0.2
elif max_blob_area < 100:
correction += 0.2
return score + correction # 補正後スコアを返す
# === スコアを1〜5の離散値に変換 ===(binning関数の設定)
def binning(score):
if score < 1.9: return 1
elif score < 2.6: return 2
elif score < 3.3: return 3
elif score < 4.0: return 4
else: return 5 # CNNの出力は連続値(回帰)だが、最終的に1〜5の評点に変換して分類評価する
# === 実験を実行するメイン関数 ===
def run_experiment(pattern, run_id): # pattern: 各学習条件の設定情報(辞書形式)
print(f"\n===== 実験 {run_id}: {pattern['name']} 開始 =====")
# 出力ディレクトリを作成
output_dir = os.path.join(BASE_RESULTS_DIR, pattern["name"])
if os.path.exists(output_dir):
shutil.rmtree(output_dir)
os.makedirs(output_dir, exist_ok=True)
for i in range(1, 6):
os.makedirs(os.path.join(output_dir, f"score{i}"), exist_ok=True)
# 学習データの読み込み
x, y = load_images_and_scores(TRAIN_FOLDER)
total_labeled = len(y) # ラベル付き画像の総数
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.2, random_state=42) # ラベル付き錆画像を学習用80%、検証用20%に分割
# === モデルの学習 or 読み込み ===
models_ensemble = [] # アンサンブルモデルを格納するリスト
for i in range(NUM_MODELS):
model_path = os.path.join(output_dir, f"ensemble_model_{i+1}.keras")
if os.path.exists(model_path): # 既に学習済みモデルがあれば読み込み
model = tf.keras.models.load_model(model_path, custom_objects={"custom_penalizing_loss": custom_penalizing_loss})
else:# 学習済みモデルが無ければ新規作成
model = create_model(i) # 新規モデル作成
callbacks = [
EarlyStopping(patience=5, restore_best_weights=True), # 5エポック改善がなければ早期終了
ModelCheckpoint(model_path, save_best_only=True) # 最良モデルを保存
]
model.fit( # 学習の実行 予め設定しておいたパラメータを呼び出す
x_train, y_train,
epochs=pattern["epochs"],
batch_size=pattern["batch_size"],
validation_data=(x_val, y_val),
callbacks=callbacks,
verbose=2
)
model.save(model_path)
models_ensemble.append(model) # アンサンブルリストに追加
# === 評価対象(テスト画像)を処理 ===
test_fnames = sorted([f for f in os.listdir(TEST_FOLDER) if f.endswith(".png") or f.endswith(".jpg")])
results = [] # 結果を格納するリスト
for fname in test_fnames:
path = os.path.join(TEST_FOLDER, fname)
img = Image.open(path).convert("RGB").resize(IMAGE_SIZE)
x_input = np.array(img) / 255.0
x_input = x_input.reshape(1, *IMAGE_SIZE, 3)
# 各モデルの予測を平均化(=アンサンブル)
preds = [m.predict(x_input, verbose=0)[0][0] for m in models_ensemble]
avg_score = np.mean(preds)
# 錆特徴量で補正
rust_ratio, rust_count, max_blob_area = extract_features(img, use_color=USE_COLOR)
adjusted_score = adjust_score_by_features(avg_score, rust_ratio, rust_count, max_blob_area)
# 範囲外スコアはスキップ
if adjusted_score < 0.00 or adjusted_score > 5.50:
print(f"⚠️ スコア範囲外: {fname} → {adjusted_score:.2f} → スキップ")
continue
final_score = binning(adjusted_score) # 回帰値を評点(1〜5)に変換
save_path = os.path.join(output_dir, f"score{final_score}", fname)
img.save(save_path) # 評点ごとのフォルダに分類して保存
# 結果を記録(CSV出力用)
results.append({
"ファイル名": fname,
"回帰スコア": round(avg_score, 3),
"補正後スコア": round(adjusted_score, 3),
"評点": final_score,
"錆割合": round(rust_ratio, 3),
"錆の数": rust_count,
"錆の最大サイズ": round(max_blob_area, 1),
})
# === 予測結果CSVを保存 ===
pd.DataFrame(results).to_csv(os.path.join(output_dir, "rust_score_with_features.csv"), index=False, encoding="utf-8-sig")
# === 評価指標の算出 ===
val_preds = [m.predict(x_val, verbose=0).flatten() for m in models_ensemble] # 検証データに対して、全モデルの出力をそれぞれ取得
y_val_pred = np.mean(val_preds, axis=0) # アンサンブル:3つのモデルの出力を平均化して最終予測値とする
# 予測スコアを1〜5のクラスラベルに変換(分類評価用)
y_val_bin = np.array([binning(s) for s in y_val_pred])
y_true_bin = np.array([binning(s) for s in y_val])
# === MAE(平均絶対誤差) ===
mae_score = mean_absolute_error(y_val, y_val_pred)
print(f"MAE:{mae_score}") # 数値予測の精度指標。小さいほど予測が正確。
# === Accuracy(単純精度) ===
from sklearn.metrics import accuracy_score, f1_score # ここで明示的に追加
acc_score = accuracy_score(y_true_bin, y_val_bin) # クラス分類として正解率を算出
# === Macro平均F1スコア ===
macro_f1 = f1_score(y_true_bin, y_val_bin, average="macro") # 各クラスのF1スコアを平均した値(不均衡データへの耐性あり)
# === 混同行列の保存(どのクラスを誤分類したか可視化) ===
pattern_dir = os.path.join("results_patterns", pattern["name"]) # パターンごとの保存フォルダを指定
os.makedirs(pattern_dir, exist_ok=True) # フォルダがなければ作成
cm = confusion_matrix(y_true_bin, y_val_bin, labels=[1, 2, 3, 4, 5]) # 1〜5評点ごとの混同行列を生成
plt.figure(figsize=(10.8, 7.2)) # 図のサイズを設定
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=[1, 2, 3, 4, 5])
disp.plot(cmap="Blues", values_format="d") # 青色系で可視化
plt.title("Confusion Matrix (Validation Set)") # タイトル
plt.savefig(os.path.join(output_dir, "confusion_matrix.png")) # 画像として保存
plt.close()
# === UMAP可視化 ===
feature_model = Model(inputs=models_ensemble[0].input, outputs=models_ensemble[0].get_layer(index=-3).output) # 高次元特徴を2次元に圧縮して分布を可視化
features_val = feature_model.predict(x_val, verbose=0) # 検証データの特徴を抽出
# CNNモデルの最終層手前の特徴ベクトルを抽出
umap = UMAP(n_neighbors=15, min_dist=0.1, random_state=42) # 近傍15点を基に2次元に埋め込み。min_dist=0.1で局所構造を保つ
embedding = umap.fit_transform(features_val) # UMAP変換実行
plt.figure(figsize=(10.8, 7.2))
scatter = plt.scatter(embedding[:, 0], embedding[:, 1], c=y_true_bin, cmap="coolwarm", s=30, alpha=0.8)
plt.colorbar(scatter, ticks=[1, 2, 3, 4, 5]) # カラーバーを追加
plt.title("UMAP Visualization of Validation Features") # タイトル
plt.savefig(os.path.join(output_dir, "umap_val.png")) # 図を保存
plt.close()
# === メモリ使用量の可視化(強制終了の原因調査用) ===
vm = psutil.virtual_memory() # システム全体のメモリ情報を取得
total_gb = vm.total / (1024 ** 3) # 総メモリ容量(GB単位)
used_gb = (vm.total - vm.available) / (1024 ** 3) # 使用中メモリ量(GB単位)
percent = vm.percent # 使用率(%)
print(f"💾 System Memory usage after {pattern['name']}: {used_gb:.2f} GB / {total_gb:.2f} GB ({percent}%)") # ターミナル上でメモリ状況を表示(メモリ不足での強制終了対策)
# === クラス別MAEと±1精度 ===
def per_class_mae(y_true, y_pred, binning_fn):
y_true_bin = np.array([binning_fn(v) for v in y_true])
y_pred_bin = np.array([binning_fn(v) for v in y_pred])
res = {}
for c in np.unique(y_true_bin):
mask = (y_true_bin == c)
if mask.sum() > 0:
res[int(c)] = mean_absolute_error(y_true[mask], y_pred[mask])
return res
def within_one_rate(y_true, y_pred, binning_fn):
y_t = np.array([binning_fn(v) for v in y_true])
y_p = np.array([binning_fn(v) for v in y_pred])
return (np.abs(y_t - y_p) <= 1).mean() # ±1段階以内に収まる割合
class_mae = per_class_mae(y_val, y_val_pred, binning)
one_acc = within_one_rate(y_val, y_val_pred, binning)
print("クラス別MAE:", class_mae)
print("±1精度:", one_acc)
# === 残差プロットと誤差分布 ===
res = y_val_pred - y_val # 残差(予測−実測)
plt.scatter(y_val, y_val_pred, s=6, alpha=0.6)
plt.plot([0, 5], [0, 5], 'r--') # 完全一致ライン
plt.xlabel("True"); plt.ylabel("Predicted")
plt.savefig(os.path.join(output_dir, "true_vs_pred.png"))
plt.close()
plt.hist(res, bins=40, color="gray")
plt.title("Residuals")
plt.savefig(os.path.join(output_dir, "residuals.png"))
plt.close()
# === モデル間誤差の相関(アンサンブル効果を定量化) ===
if len(val_preds) >= 2:
from scipy.stats import pearsonr # ピアソン相関係数
errors = [np.abs(y_val - p) for p in val_preds]
corr = np.zeros((len(errors), len(errors))) # 相関行列
for i in range(len(errors)):
for j in range(len(errors)):
corr[i, j], _ = pearsonr(errors[i], errors[j])
pd.DataFrame(corr).to_csv(os.path.join(output_dir, "error_corr.csv"), index=False)
print("誤差相関行列を保存しました")
# === モデル・変数を明示的に解放 ===
del models_ensemble # モデルリストを削除
del x_train, x_val, y_train, y_val # データも削除
tf.keras.backend.clear_session() # TensorFlowセッションをリセット
gc.collect() # Pythonのガーベジコレクションを実行
print(f"===== 実験 {run_id}: {pattern['name']} 完了 =====\n")
# === モデル・データを完全解放 ===
del models_ensemble
del x_train, x_val, y_train, y_val
tf.keras.backend.clear_session()
gc.collect()
print(f"===== 実験 {run_id}: {pattern['name']} 完了 =====\n")
# === 実験条件と評価結果の記録 ===
summary = {
"name": pattern["name"], # 学習パターン名
"epochs": pattern["epochs"], # エポック数
"batch_size": pattern["batch_size"], # バッチサイズ
"num_aug": pattern["num_aug"], # 水増し枚数
"rotation": pattern["rotation"], # 回転角度
"brightness": str(pattern["brightness"]), # 明るさ(tupleを文字列化)
"width_shift": str(pattern["width_shift"]), # 横移動範囲
"height_shift": str(pattern["height_shift"]), # 縦移動範囲
"total_train_samples": total_labeled * pattern["num_aug"], # 水増し後の画像枚数
"mae": mae_score, # 平均絶対誤差
"accuracy": acc_score, # 正答率
"macro_f1": macro_f1, # Macro平均F1スコア
"class_mae": str(class_mae), # 評点別のmae表示
"within_one_acc": one_acc, # ±1精度
"datetime": str(datetime.datetime.now()) # 実行終了時間を記録
}
pd.Series(summary).to_csv(os.path.join(output_dir, "summary.csv")) # この学習条件の情報をCSVに保存
return summary # 実験結果の概要を返す
# === メイン処理 ===
if __name__ == "__main__":
all_results = [] # 全実験の結果をまとめるリスト
for idx, pat in enumerate(patterns): # 各パターンを順に実行
summary = run_experiment(pat, idx)
all_results.append(summary)
# === 全実験の集計結果をCSVで保存 ===
df_all = pd.DataFrame(all_results)
df_all.to_csv(os.path.join(BASE_RESULTS_DIR, "all_results.csv"), index=False, encoding="utf-8-sig")
print(f"✅ 全パターンの集計結果を {os.path.join(BASE_RESULTS_DIR, 'all_results.csv')} に保存しました。")
・results_patterns1-2 # 各学習パターンの結果をまとめたフォルダ。どの条件でどんな結果が出たかを一覧で追えるよう整理されている。 | |__ pattern_1 # 1つの学習パターン(=特定の学習条件セット)の出力結果で、この中にそのパターンで作成されたモデルや評価結果が保存されている。 | | | |__ ensemble_model_1.keras, ensemble_model_2.keras, ... # 各アンサンブルモデルの学習済みウェイトファイル | | # CNNモデルが学習を終えた状態で保存されており、 | | # .keras 形式は TensorFlow の新しい保存方式で再学習・再評価・転移学習などに再利用できる。 | | # ensemble_model_1〜3 はそれぞれ異なる初期値で学習し、後で平均化してアンサンブルを構成。 | | | |_ confusion_matrix.png # 混同行列(分類の正誤マトリクス) | | # 評点(1〜5)の分類結果と実際の正解を比較した図で、対角線上に多く分布していれば正解率が高い。 | | # どの評点を誤って別の評点として判断したのかが直感的に理解できるようになっている。 | | | |_ error_corr.csv # 各CNNモデル同士の 誤差の相関行列 値が1.0に近いほどモデルの誤差傾向が似ている(=多様性が低い)ことを意味し、 | | # アンサンブル効果を上げるにはこの相関を下げることが重要。 | | | |_ residuals.png # 予測誤差(残差)分布を表すヒストグラム | | # 横軸は予測値 − 実測値, 縦軸はその誤差が出現した回数を表しており、分布が「左右対称で0付近に集中」していれば良好な学習といえる。 | | # 一方で偏りがある場合は特定の評点を過小・過大評価している可能性を示す。 | |_ rust_score_with_features.csv # 各テスト画像に対する 推論結果一覧表 機械学習結果+画像解析結果が一緒に記録されている。 | | | |_ summary.csv # そのパターンでの 学習条件と指標の要約 | | | |_ true_vs_pred.png # 実測スコア(横軸)と予測スコア(縦軸)の散布図 理想は赤い破線(完全一致ライン)上に点が並ぶこと。 | | # 大きく外れている点は「誤予測」サンプルであり、そこから誤差の原因分析が可能。 | | | |_ umap_val.png # 検証データのCNN特徴量を UMAP により2次元化した可視化図 | # 点の色は実際のクラス(1〜5)を表しており、クラスごとに明確にまとまっていれば特徴抽出がうまく機能している証拠で | # 混ざっている場合はモデルがクラス間を区別できていない可能性あり。 | |_ pattern_2___ ensemble_model_1.keras, ensemble_model_2.keras, ... | |_ confusion_matrix.png | |_ ... |_ ...
ラベル付き画像全114枚から1枚あたり50枚水増ししたのち再度水増しを行って学習させた(2回水増し)。2回目の水増しは枚数を変化させることで学習結果に影響を及ぼすのか調べ、1, 2, 3, 5, 10, 15, 20, 30, 40, 50, 60, 70枚とそれぞれ水増しした学習が完了したのでその結果を以下の表に示す。

・補正値 |・binning
def adjust_score_by_features(score, rust_ratio, rust_count, max_blob_area): |def binning(score):
correction = 0.0 | if score < 1.9: return 1
| elif score < 2.6: return 2
if score >= 4.5: | elif score < 3.3: return 3
# 高スコアはそのまま返す(補正・clipなし) | elif score < 4.0: return 4
return score | else: return 5
|
if rust_ratio >= 0.60: |
correction -= 0.5 |
elif 0.45 <= rust_ratio < 0.60: |
correction -= 0.3 |
elif 0.25 <= rust_ratio < 0.45: |
correction -= 0.1 |
elif rust_ratio < 0.05: |
correction += 0.3 |
|
if rust_count >= 1000: |
correction -= 0.2 |
elif 500 <= rust_count < 1000: |
correction -= 0.1 |
elif rust_count < 100: |
correction += 0.1 |
|
if max_blob_area >= 15000: |
correction -= 0.4 |
elif 8000 <= max_blob_area < 15000: |
correction -= 0.2 |
elif max_blob_area < 100: |
correction += 0.2 |
|
return score + correction |











| 画像 | 補正前評点 | 補正後評点 | 回帰スコア | 補正後スコア | 錆割合 | 錆数 | 最大錆 |
| 1-01.png | 3 | 2 | 3.102 | 2.302 | 0.719 | 33 | 87309.0 |
| 2-01.png | 3 | 2 | 3.151 | 2.451 | 0.379 | 1480 | 20794.0 |
| 3-01.png | 3 | 2 | 3.196 | 2.396 | 0.817 | 12 | 88528.0 |
| 4-01.png | 4 | 3 | 3.455 | 2.655 | 0.914 | 1 | 89187.5 |
| 5-01.png | 3 | 2 | 3.105 | 2.305 | 0.953 | 2 | 89268.5 |
| 1-11.jpg | 1 | 1 | 0.967 | 0.467 | 0.359 | 359 | 19832.0 |
| 2-11.jpg | 3 | 3 | 2.762 | 2.662 | 0.274 | 451 | 3808.5 |
| 2-12.jpg | 3 | 3 | 2.882 | 2.682 | 0.266 | 722 | 4102.0 |
| 3-11.jpg | 4 | 4 | 3.575 | 3.375 | 0.163 | 1348 | 527.5 |
| 4-11.jpg | 5 | 5 | 4.933 | 4.933 | 0.042 | 707 | 236.5 |
| 5-11.jpg | 5 | 5 | 4.936 | 4.936 | 0.005 | 178 | 153.5 |
補正関数を組み込んでも評点が変化することはあまりないことが分かったため、今後補正関数の導入を見送ることとする。ただし錆割合 , 錆数 , 最大錆 の抽出に関しては上手く特徴量を画像から抽出できているか判断する材料となり得るため今後も組み込むこととする。モノクロ画像に関して的中したのは全6枚のうち2枚と良い結果は得られなかった。しかし画像に付けたラベルは目視であり第三者的な目線から評価を行っていないため、ラベルと実際の評点が異なる可能性もある。逆に目視評価で評点1〜5付けるよりも学習データをもとに評点を付けたほうが精度が高くあってほしい。
現地調査で撮影したカラーの錆画像を台形補正するスクリプトを作成した。だが画像によっては上手く補正できないこともあるのでその原因究明と補正成功率の向上を20日以降に行う。補正の詳しい内容については明後日以降記載する。
台形変換のスクリプトがとりあえず完成したので貼り付けておく。今後はこれをもとに改良を重ねていくつもり ★マークが付いている行はパラメータを任意で変更可能
◯指定フォルダ内の画像に対して「白いプレート枠を検出して可視化画像として保存する処理」の主な流れ
1,画像読み込み
2,グレースケール変換と二値化
3,ノイズ除去(モルフォロジー演算+ラベリング)
4,最大矩形領域の抽出
5,結果画像の保存
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
import cv2
import numpy as np
import os
import shutil
from glob import glob
# === 設定 ===
INPUT_DIR = "drone_images" # ★入力画像フォルダ
OUTPUT_DIR = "processed_patches3" # ★出力フォルダ
REF_WIDTH = 1000 # ★出力画像の横サイズ
REF_HEIGHT = 750 # ★出力画像の縦サイズ
os.makedirs(OUTPUT_DIR, exist_ok=True)
# === フォルダーの削除・作成 ===
folder_name = OUTPUT_DIR
if os.path.exists(folder_name):
shutil.rmtree(folder_name)
print(f"既存のフォルダ '{folder_name}' を削除しました。")
os.makedirs(folder_name, exist_ok=True)
print(f"新しいフォルダ '{folder_name}' を作成しました。")
# === 1. プレート領域のマスク処理 ===
def mask_plate_region(img, threshold_mode="otsu"): #★しきい値の解釈方法("otsu" または "adaptive")
"""
撮影画像から白いプレート枠領域を抽出してマスク化する。
"""
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #カラー画像をグレースケール化
#OpenCVでは通常BGR形式なので、cv2.COLOR_BGR2GRAYを指定して輝度情報のみを抽出。
blur = cv2.GaussianBlur(gray, (5, 5), 0) #★ノイズを抑制しスムーズな二値化を行うためにガウシアンぼかしを適用。
#(ここでの (5,5) を (3,3) や (7,7) などに変更すると、ノイズ除去の度合いが変化)
if threshold_mode == "otsu":
_, binary = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) #大津の二値化法で明暗を自動的に分離。
elif threshold_mode == "adaptive":
binary = cv2.adaptiveThreshold(blur, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2) #照明が不均一な場合でも適応的にしきい値を割り当てる方式。
else:
raise ValueError("threshold_mode must be 'otsu' or 'adaptive'") #モード指定以外のパラメータが渡された場合に警告。
# 白黒反転(白枠が白くなるように)
if np.mean(binary) < 127:
binary = cv2.bitwise_not(binary)
return binary #最終的なマスク画像(二値化画像)を返す。
# === 2. ノイズ除去処理 ===
def remove_noise(binary_mask):
"""
二値化画像から小さなノイズを除去し、白枠を明確化する。
"""
kernel = np.ones((5, 5), np.uint8) #★モルフォロジー演算用の正方カーネルを生成。(小さいと細かく、大きいと滑らかに)
opened = cv2.morphologyEx(binary_mask, cv2.MORPH_OPEN, kernel, iterations=2) #★ Opening:白ノイズ除去(iterations:繰り返し回数。強さを調整できる)
closed = cv2.morphologyEx(opened, cv2.MORPH_CLOSE, kernel, iterations=2) #★ Closing:枠線の途切れ補完(上記と同様)
# ラベリング処理で各領域を集計し、面積500以上の領域だけを残す。プレート以外の小さいブロブは除外。
num_labels, labels, stats, _ = cv2.connectedComponentsWithStats(closed)
cleaned = np.zeros_like(closed)
for i in range(1, num_labels): # 0は背景
area = stats[i, cv2.CC_STAT_AREA]
if area > 500:
cleaned[labels == i] = 255 #★ ここの 500 は小さいノイズ領域を除外する閾値で、画像スケールに合わせて調整可能。
return cleaned #クリーンなマスク画像を返す。
# === 3. 輪郭の取得と近似化 ===
def detect_plate_contour(img, cleaned_mask):
"""
白枠プレートの輪郭を検出し、最も大きな矩形を返す。
"""
contours, _ = cv2.findContours(cleaned_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) #外側の輪郭を抽出。
if not contours:
print("⚠️ 輪郭が検出されませんでした。")
return img, None
contours = sorted(contours, key=cv2.contourArea, reverse=True) # 面積順にソートして最大の輪郭を選ぶ。
# 最も大きい輪郭を選択
largest_contour = contours[0]
epsilon = 0.02 * cv2.arcLength(largest_contour, True) #★ 小さくすると輪郭近似がより正確に、大きくすると単純化される。
approx = cv2.approxPolyDP(largest_contour, epsilon, True) #輪郭を滑らかに近似(多角形化)してノイズを減らす。
# 4頂点に近い輪郭のみ採用し、緑枠で描画し角座標を出力。
contour_img = img.copy()
if len(approx) == 4:
cv2.drawContours(contour_img, [approx], -1, (0, 255, 0), 4)
pts = approx.reshape(4, 2)
print(f"🟩 四角形の頂点座標: {pts}")
return contour_img, pts
else:
print(f"⚠️ 4頂点ではありません({len(approx)}点) → スキップ")
cv2.drawContours(contour_img, [largest_contour], -1, (0, 0, 255), 3)
return contour_img, None #矩形でない領域は赤枠で描画しスキップ。
# === 4. メイン処理 ===
for fname in os.listdir(INPUT_DIR):
if not fname.lower().endswith((".jpg", ".jpeg", ".png")):
continue #入力ディレクトリを走査し、画像ファイルのみを処理。
img_path = os.path.join(INPUT_DIR, fname)
img = cv2.imread(img_path) #画像を読み込み(BGR形式)。
if img is None:
print(f"⚠️ 読み込み失敗: {fname}")
continue
mask = mask_plate_region(img, threshold_mode="otsu") #ステップ1: マスク化
cleaned = remove_noise(mask) #ステップ2: ノイズ除去
contour_img, pts = detect_plate_contour(img, cleaned) #ステップ3: 輪郭検出・近似化
# --- 保存 ---
save_path = os.path.join(OUTPUT_DIR, f"contour_{fname}")
cv2.imwrite(save_path, contour_img)
print(f"✅ 輪郭検出結果を保存しました: {save_path}")
# === 3. 輪郭の取得と近似化 ===
def detect_plate_contour(img, cleaned_mask):
"""
白枠プレートの輪郭を検出し、内側スケール矩形のみを抽出。
外枠(画像外周)は無視。
条件:
- 面積が 20000〜1450×1060 の範囲
- アスペクト比が 1.0〜a の範囲
- 図形中心が画像の外周b%以内でない
- 各角の角度が c°〜d° の範囲
"""
h, w = img.shape[:2]
max_allowed_area = 1450 * 1060
min_allowed_area = 20000
# --- ① 外枠除外マスク ---
inner_mask = np.zeros_like(cleaned_mask)
margin = int(min(h, w) * 0.12) # 外周12%を無視
inner_mask[margin:h - margin, margin:w - margin] = 255
masked = cv2.bitwise_and(cleaned_mask, inner_mask)
# --- ② 輪郭検出 ---
contours, _ = cv2.findContours(masked, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if not contours:
print("⚠️ 輪郭が検出されませんでした。")
return img, None
valid_candidates = []
for cnt in contours:
area = cv2.contourArea(cnt)
if area < min_allowed_area or area > max_allowed_area:
continue
rect = cv2.minAreaRect(cnt)
(cx, cy), (rw, rh), angle = rect
# --- ③ 中心位置チェック(外周に寄りすぎていないか) ---
if cx < margin or cx > (w - margin) or cy < margin or cy > (h - margin):
continue
# --- ④ アスペクト比チェック ---
aspect_ratio = max(rw, rh) / (min(rw, rh) + 1e-6)
if not (1.0 <= aspect_ratio <= 2.5):
continue
# --- ⑤ 近似と角度判定 ---
epsilon = 0.02 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
if len(approx) != 4:
continue
pts = approx.reshape(4, 2)
angles = []
for i in range(4):
p1, p2, p3 = pts[i], pts[(i + 1) % 4], pts[(i + 2) % 4]
v1, v2 = p1 - p2, p3 - p2
cos_angle = np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2) + 1e-6)
angle = np.degrees(np.arccos(np.clip(cos_angle, -1.0, 1.0)))
angles.append(angle)
if all(69 <= a <= 111 for a in angles):
valid_candidates.append((area, pts))
# --- ⑥ 最も適した候補を選択 ---
if not valid_candidates:
print("⚠️ 有効な内枠が見つかりませんでした。")
return img, None
best_area, best_pts = max(valid_candidates, key=lambda x: x[0])
contour_img = img.copy()
cv2.drawContours(contour_img, [best_pts.astype(int)], -1, (0, 255, 0), 4)
print(f"🟩 内枠矩形を検出(面積={best_area:.0f}, アスペクト比={aspect_ratio:.2f})")
return contour_img, best_pts
上記に示したスクリプトを Scalehosei3.py と定義し撮影したカラーの錆画像からカラースケールの内側枠を抽出・色,補正できる前段階まで持っていくことができた。







色補正を行う前段階としてカラースケールのカラーを切り抜くまでのスクリプトを作成したので貼り付けておく。
import cv2
import numpy as np
import os
import shutil # OpenCV・NumPy・OS操作・フォルダ削除を扱うための基本ライブラリをインポート
INPUT_DIR = "processed_patches3"
OUTPUT_DIR = "processed_patches4"
os.makedirs(OUTPUT_DIR, exist_ok=True) # 入力・出力フォルダの指定 出力フォルダが存在しなければ新規作成
# === フォルダーの削除・作成 ===
folder_name = OUTPUT_DIR
if os.path.exists(folder_name):
shutil.rmtree(folder_name)
print(f"既存のフォルダ '{folder_name}' を削除しました。")
os.makedirs(folder_name, exist_ok=True)
print(f"新しいフォルダ '{folder_name}' を作成しました。")
def detect_and_extract_color_scale(img): # メイン関数 画像からカラースケール領域(右端の赤・黄・緑・青)を検出して切り抜く。
h, w = img.shape[:2]
roi = img[:, int(w * 0.65):] # 画像の右側35%を ROI(Region of Interest)として抽出 カラースケールは右端にあるため。
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV) # BGR(OpenCV標準)を HSV 色空間に変換することで色の判別がしやすくなる。
color_ranges = {
'red1': ((0, 100, 100), (10, 255, 255)),
'red2': ((160, 100, 100), (180, 255, 255)),
'yellow': ((20, 100, 100), (40, 255, 255)),
'green': ((40, 50, 50), (90, 255, 255)), # HSVで赤・黄・緑・青を検出する範囲を定義。
'blue': ((90, 50, 50), (150, 255, 255)), # HSVにおける色相では赤は0°付近と180°付近の2か所に分かれるため、red1 と red2 の2つの範囲を指定。
}
mask_red = cv2.bitwise_or(cv2.inRange(hsv, *color_ranges['red1']), cv2.inRange(hsv, *color_ranges['red2']))
mask_yellow = cv2.inRange(hsv, *color_ranges['yellow'])
mask_green = cv2.inRange(hsv, *color_ranges['green']) # 各色(赤・黄・緑・青)の範囲で二値マスク(その色だけ白)を作成。
mask_blue = cv2.inRange(hsv, *color_ranges['blue']) # cv2.inRange は指定範囲内のピクセルを255(白)にする。
combined_mask = cv2.bitwise_or(cv2.bitwise_or(mask_red, mask_yellow), cv2.bitwise_or(mask_green, mask_blue)) # 全てのマスクを統合 4色のどれかに該当する部分が白になる。
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5)) # 小さい穴を埋めるモルフォロジー演算(Closing)。
combined_mask = cv2.morphologyEx(combined_mask, cv2.MORPH_CLOSE, kernel) # カラースケール領域をより一体的な白領域に整形。
contours, _ = cv2.findContours(combined_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 白領域の輪郭を抽出。RETR_EXTERNAL なので外側の輪郭のみ取得。
if not contours:
print("カラースケール領域検出なし")
return img, None
candidates = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
(cx, cy), (width, height), angle = rect # 各輪郭に外接する最小回転矩形(斜めでもOK)を求める。
if width == 0 or height == 0:
continue # 面積ゼロのものはスキップ。
aspect_ratio = max(width, height) / min(width, height) # 縦横比と面積を計算。
area = width * height # カラースケールのような縦長矩形を選別するために使う。
if area > 0.001 * roi.shape[0] * roi.shape[1] and 3.0 <= aspect_ratio <= 12.0:
box = cv2.boxPoints(rect)
box = np.int0(box) # 面積と縦横比の条件を満たす矩形のみを候補として保存。
candidates.append((area, box, rect)) # 縦長(アス比3〜12)であることが条件。
if not candidates:
print("適合するカラースケール候補がありません")
return img, None
largest_candidate = max(candidates, key=lambda c: c[0]) # 条件を満たす候補リストから最大面積のものを選択
area, box, rect = largest_candidate # 条件を満たした候補の中から最も大きい矩形(カラースケールとみなす)を選択。
box[:,0] += int(w * 0.65) # 元画像座標に変換 → ROIは右端35%だったため、座標を元画像スケールに戻す。
img_with_box = img.copy()
cv2.drawContours(img_with_box, [box], 0, (0,255,0), 3) # 検出したカラースケール領域を緑の枠で可視化。
width = int(rect[1][0])
height = int(rect[1][1])
if width == 0 or height == 0:
print("切り出し用サイズ不正")
return img_with_box, None # 切り抜きサイズが0の場合はスキップ。
dst_pts = np.array([[0,0],[width-1,0],[width-1,height-1],[0,height-1]], dtype=np.float32)
src_pts = box.astype(np.float32) # 透視変換行列(台形→長方形)を計算。
M = cv2.getPerspectiveTransform(src_pts, dst_pts) # スケールを正面視点で切り抜くため。
extracted = cv2.warpPerspective(img, M, (width, height))
extracted = cv2.resize(extracted, (height, width)) # 縦横を入れ替えてリサイズ → 台形補正して切り抜き、縦横を整形。
return img_with_box, extracted # 枠付き画像(確認用)と抽出したスケール画像を返す。
def process_images(in_dir, out_dir): # 複数画像を一括処理する関数。
os.makedirs(out_dir, exist_ok=True)
for fn in os.listdir(in_dir):
if fn.lower().endswith(('.png','.jpg','.jpeg','.tif')): # 対象フォルダ内の画像ファイルをループ処理。
path_in = os.path.join(in_dir, fn)
path_out = os.path.join(out_dir, fn)
path_crop = os.path.join(out_dir, "crop_"+fn) # 入力画像、枠付き画像、切り抜き画像のパスをそれぞれ定義。
img = cv2.imread(path_in)
if img is None:
print(f"{fn} 読み込み失敗")
continue
img_boxed, crop_img = detect_and_extract_color_scale(img) # カラースケールの検出・切り抜きを実行。
cv2.imwrite(path_out, img_boxed)
print(f"{fn} に枠を描画") # 枠付き画像を保存。
if crop_img is not None:
cv2.imwrite(path_crop, crop_img)
print(f"{fn} の切り出し領域を保存") # 切り抜き画像が得られた場合のみ保存。
if __name__ == "__main__": #メイン実行部。
process_images(INPUT_DIR, OUTPUT_DIR) # スクリプトを直接実行したときにINPUT_DIR内の画像を処理して結果をOUTPUT_DIRに保存。
まとめると
1, 右側35%領域を「カラースケール候補」として抽出。
2, HSVで赤・黄・緑・青の色領域を検出。
3, 条件(面積・縦横比)を満たす最も大きな矩形をカラースケールと判断。
4, 緑枠で描画して切り抜き画像を保存。
このスクリプトを通じて画像を変換させると元画像(入力画像)から枠付き画像、スケール切り抜き画像がそれぞれ出力される。












スクリプトの案内
とりあえず色補正を行う所までスクリプトを組むことができたが、補正するとどうしても画面が真っ白になってしまう
カラースケールを純色にRGBの3×3の行列で変換した後その行列で画像全体の色補正を行った。このすぐ上にある4枚の画像を補正した結果を貼り付けておくが、あくまで作成した補正スクリプトは完成版ではないのでこれから微々たる修正を重ねていくと思う。全体的に画像に赤みがかかっているがどうか こんなのものなのか




色補正スクリプトの方でRGB毎に影響の強弱を付けられるようにしたが限界があった。緑を純色に近づけようとすると青が黒に近くなり、青を純色にしようとすると緑がシアンに近づいてしまうという状況が発生してしまったのでなにか別のアプローチで補正する必要がありそう。変換行列の作成方法を最小二乗法から非線形多項式補正・ガンマ補正に変えて色補正を行うべきなのか。
色補正後の赤みをある程度抑えられ、先に色補正を行ってから錆の枠を抽出して台形変換を行った。カラースケールのカラーだが元々が純色でないため無理やり補正で255と0表示に持っていった結果、補正画像において赤が強く反映されてしまった。なのですべての画像を純色にする必要はないのではとアドバイスをもらった。












| モデル名 | MAE | 正答率 | F1スコア |
| EfficientNetV2S | 0.3029 | 0.7865 | 0.7623 |
| DenseNet121 | 0.0888 | 0.9912 | 0.9891 |
| MobileNetV3Large | 0.1656 | 0.9438 | 0.9409 |
| ensemble | 0.1456 | 0.9859 | 0.9827 |
| モデル名 | MAE | 正答率 | F1スコア |
| DenseNet121 | 0.0841 | 0.9859 | 0.9819 |
| InceptionResNetV2 | 0.1649 | 0.9675 | 0.9651 |
| Xception | 0.1215 | 0.9772 | 0.9743 |
| ensemble | 0.0988 | 0.9938 | 0.9923 |
| モデル名 | MAE | 正答率 | F1スコア |
| 旧モデルDenseNet121 | 0.0888 | 0.9912 | 0.9891 |
| 新モデルDenseNet121 | 0.0841 | 0.9859 | 0.9819 |
同じ DenseNet121 を用いているのに結果が微妙に異なるのは学習過程でわずかに異なる条件が発生しているためであり、いくつか要因があると考えられている。
◯主原因1:初期化の乱数
TensorFlow / Keras の重み初期値は乱数で生成されることで同じモデル構造・データでも初期の重みが異なると学習経路も変わるため最終結果が微妙に変化する。特にMAEやF1が小数点3桁単位で異なるのは「乱数初期化」が主な原因とされる。
◯主原因2:データ分割のランダム性
train_test_split を使うとrandom_state=42 のように固定しない限り訓練データと検証データが毎回異なる。評価指標(MAE, Accuracyなど)は検証セットに依存するため、分割が違うとスコアも変化する。
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.2, random_state=42) #学習スクリプトでこのように設定する
◯主原因3:アンサンブル全体の重み干渉
アンサンブル処理内でモデル学習順序が異なる, または他のモデルの出力が同じフォルダに上書きされるなど微妙な環境差があると挙動が変化するが、この差はMAE 0.01未満レベルで収まるケースがほとんど。
上記の条件下で新・旧モデルのDenseNet121を比較した。
| モデル名 | MAE | 正答率 | F1スコア |
| EfficientNetV2S | 0.332241619945153 | 0.687170474516696 | 0.664742780762101 |
| DenseNet121 | 0.123156605893157 | 0.806678383128295 | 0.782791670207675 |
| MobileNetV3Large | 0.19573938891256 | 0.783831282952548 | 0.762552116173173 |
| Ensemble | 0.177296200058912 | 0.807557117750439 | 0.779550819835585 |
| モデル名 | MAE | 正答率 | F1スコア |
| InceptionResNetV2 | 0.153177455220403 | 0.79701230228471 | 0.759486069791022 |
| DenseNet121 | 0.147729756383773 | 0.794376098418278 | 0.766856817460948 |
| Xception | 0.142235872050986 | 0.808435852372584 | 0.778707125381728 |
| Ensemble | 0.12868636939779 | 0.812829525483304 | 0.783772204597505 |
| モデル名 | MAE | 正答率 | F1スコア |
| 旧モデルDenseNet121 | 0.123156605893157 | 0.806678383128295 | 0.782791670207675 |
| 新モデルDenseNet121 | 0.147729756383773 | 0.794376098418278 | 0.766856817460948 |
| (新・旧)の差 | 0.024573150490616 | -0.0123022847100169 | -0.015934852746727 |
両学習モデルで乱数シードを固定し学習条件を統一した上で訓練を実施した。しかし同一スクリプト・同一データセット・同一ハイパーパラメータを用いても、DenseNet121の評価結果が完全には一致しなかった。原因として考えられるのがTensorFlowおよびKerasにおける内部処理の一部が非決定的(non-deterministic)な演算を含むことに起因する。以下の要素が主な原因である。
◯GPU演算の非決定性:CuDNN(NVIDIAのディープラーニングライブラリ)は高速化のため一部の畳み込み演算(特にConv2DやBatchNormalization)において非決定的なアルゴリズムを選択することがある。そのため、同じ乱数シードを設定してもGPU上での学習結果にわずかな差異が生じる可能性がある。
◯os, numpy, tensorflow のランダム初期化:スクリプトでは set_global_determinism関数によってPython, NumPy, TensorFlowの乱数シードを固定しているが、モデルの初期重み(特にImageNet事前学習済みモデルのロード時)には依然として一部乱数依存の初期化ステップが残る場合がある。
◯並列スレッドおよびGPUメモリスケジューリング:マルチスレッド環境ではスレッドの実行順序や演算スケジューリングが完全には制御できないため、浮動小数点誤差の蓄積順序が異なることで最終的なモデル出力に微小な差異が生じる。
◯EarlyStoppingとModelCheckpointの影響:各エポック終了時の検証損失に基づいてモデルが保存されるが、非決定的な誤差伝播によりわずかに異なるタイミングで「最良モデル」と判定されるケースがある。
宮城県の橋梁調査データをもらい学習の事前準備を行った
色補正・台形変換に関する各スクリプトに変更を加えたので以下に示す スクリプトの実行手順はScalehosei○.pyの○が順番を表している。
import cv2 #OpenCV(画像処理用ライブラリ)をインポート
import numpy as np #NumPy(数値計算用ライブラリ)をインポート
import os #OS関連の操作(ファイルパスなど)用ライブラリをインポート
import shutil #フォルダ削除などの高機能ファイル操作を行う標準ライブラリをインポート
INPUT_DIR = "drone_images" #入力画像を格納したフォルダ名を指定
OUTPUT_DIR = "processed_patches1" #処理後のファイル保存フォルダ名を指定
os.makedirs(OUTPUT_DIR, exist_ok=True) #出力フォルダがなければ新規作成
# === フォルダーの削除・作成 ===
folder_name = OUTPUT_DIR
if os.path.exists(folder_name):
shutil.rmtree(folder_name) #既存フォルダがあれば再帰的に中身ごと削除
print(f"既存のフォルダ '{folder_name}' を削除しました。")
os.makedirs(folder_name, exist_ok=True) #新たに出力フォルダを再作成
print(f"新しいフォルダ '{folder_name}' を作成しました。")
# === 拡張子統一 (.JPG, .JPEG → .jpg) ===
def unify_extensions(folder): #指定フォルダ内の画像拡張子を統一する関数
for fname in os.listdir(folder): #中のファイル名を走査
old_path = os.path.join(folder, fname) #フルパスを作成
if not os.path.isfile(old_path): #サブフォルダ等はスキップ
continue
base, ext = os.path.splitext(fname) #ファイル名と拡張子を小文字分離
ext_lower = ext.lower()
if ext_lower in [".jpeg", ".jpg", ".png", ".tif"]: #対象拡張子か判定
new_path = os.path.join(folder, base + ".jpg") #新しいファイル名を「.jpg」で作成
if new_path != old_path: #名前が違えばリネーム実行
os.rename(old_path, new_path)
print(f"🔄 拡張子統一: {fname} → {os.path.basename(new_path)}")
unify_extensions(INPUT_DIR) #入力フォルダ内拡張子を一括変換
def detect_and_extract_color_scale(img): #画像からカラースケール部分を抽出し、枠付き画像と抽出画像を返す
h, w = img.shape[:2]
roi = img[:, int(w * 0.65):] #画像右側(横65%より右)領域をROIとして選択
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV) #色判別用にHSV色空間に変換
color_ranges = { #「赤・黄・緑・青」検出用の閾値(範囲)を辞書で定義
'red1': ((0, 120, 80), (10, 255, 255)),
'red2': ((160, 120, 80), (180, 255, 255)),
'yellow': ((20, 150, 150), (35, 255, 255)), # 白っぽい領域除外
'green': ((45, 80, 80), (85, 255, 255)),
'blue': ((90, 80, 80), (130, 255, 255)),
}
mask_red = cv2.bitwise_or(cv2.inRange(hsv, *color_ranges['red1']), cv2.inRange(hsv, *color_ranges['red2']))
mask_yellow = cv2.inRange(hsv, *color_ranges['yellow'])
mask_green = cv2.inRange(hsv, *color_ranges['green'])
mask_blue = cv2.inRange(hsv, *color_ranges['blue']) #各色範囲についてヒストグラムマスク作成
combined_mask = cv2.bitwise_or(cv2.bitwise_or(mask_red, mask_yellow), cv2.bitwise_or(mask_green, mask_blue)) #各マスクを結合し、カラースケール全域を一括検出
# --- ② ノイズ除去・スムージング ---
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5)) #輪郭強調・ノイズ除去用カーネルを生成
combined_mask = cv2.morphologyEx(combined_mask, cv2.MORPH_OPEN, kernel)
combined_mask = cv2.morphologyEx(combined_mask, cv2.MORPH_CLOSE, kernel) #マスク画像に「開」「閉」処理でノイズ除去+領域平滑化
contours, _ = cv2.findContours(combined_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) #領域の輪郭情報抽出
candidates = [] #候補リスト準備
for cnt in contours: #各輪郭それぞれについて検査
rect = cv2.minAreaRect(cnt) #最小外接矩形のパラメータ取得
(cx, cy), (width, height), angle = rect
if width == 0 or height == 0:
continue
aspect_ratio = max(width, height) / (min(width, height) + 1e-6)
area = width * height #アスペクト比や面積などで「縦長・サイズ条件」を満たす矩形だけ候補に採用。
# --- ③ 縦長・面積条件 ---
if area > 0.005 * roi.shape[0] * roi.shape[1] and 3.5 <= aspect_ratio <= 12.0:
box = cv2.boxPoints(rect)
box = np.int0(box)
candidates.append((area, box, rect))
# === 自動検出失敗時の手動選択 ===
if not candidates: #候補がない場合は手動選択モードへ
print("⚠️ 適合するカラースケール候補がありません。手動で4点を選択してください。")
manual_points = [] #マウスクリック位置を格納するリスト
#以下「右クリックで追加・左クリックで取り消し」というインタラクション処理 4点選択完了で射影変換して切り出し抽出画像を返却(失敗時はスキップ)
def mouse_callback(event, x, y, flags, param):
if event == cv2.EVENT_RBUTTONDOWN: # 右クリックで追加
manual_points.append((x, y))
cv2.drawMarker(param, (x, y), (0, 255, 0), cv2.MARKER_TILTED_CROSS, 20, 2)
cv2.imshow("manual_select", param)
print(f"✅ {len(manual_points)}点目 ({x},{y})")
elif event == cv2.EVENT_LBUTTONDOWN: # 左クリックで削除
if manual_points:
manual_points.pop()
print(f"↩️ 直前の点を削除。残り{len(manual_points)}点。")
temp = img.copy()
for px, py in manual_points:
cv2.drawMarker(temp, (px, py), (0, 255, 0), cv2.MARKER_TILTED_CROSS, 20, 2)
cv2.imshow("manual_select", temp)
temp = img.copy()
cv2.imshow("manual_select", temp)
cv2.setMouseCallback("manual_select", mouse_callback, temp)
print("🖱️ 右クリックで4点選択、左クリックで直前をキャンセル。完了後にEnterキー。")
while True:
key = cv2.waitKey(0)
if key in [13, 10]: # Enterキーで確定
break
cv2.destroyWindow("manual_select")
if len(manual_points) != 4:
print("⚠️ 4点が選択されませんでした。スキップします。")
return img, None
src_pts = np.array(manual_points, dtype=np.float32)
w_scale = int(np.linalg.norm(src_pts[0] - src_pts[1]))
h_scale = int(np.linalg.norm(src_pts[1] - src_pts[2]))
dst_pts = np.array([[0,0],[w_scale-1,0],[w_scale-1,h_scale-1],[0,h_scale-1]], dtype=np.float32)
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
extracted = cv2.warpPerspective(img, M, (w_scale, h_scale))
cv2.destroyAllWindows()
return img, extracted
# --- 自動検出成功時 ---
#最も大きい領域を選び元画像上に枠を描画して射影変換で抽出画像作成 必要なら縦横比を調整して返却
area, box, rect = max(candidates, key=lambda c: c[0])
box[:,0] += int(w * 0.65)
img_with_box = img.copy()
cv2.drawContours(img_with_box, [box], 0, (0,255,0), 3)
width = int(rect[1][0])
height = int(rect[1][1])
dst_pts = np.array([[0,0],[width-1,0],[width-1,height-1],[0,height-1]], dtype=np.float32)
src_pts = box.astype(np.float32)
M = cv2.getPerspectiveTransform(src_pts, dst_pts)
extracted = cv2.warpPerspective(img, M, (width, height))
extracted = cv2.resize(extracted, (height, width)) # 縦横を統一
return img_with_box, extracted
def process_images(in_dir, out_dir): #全画像を一括処理する関数
os.makedirs(out_dir, exist_ok=True)
for fn in os.listdir(in_dir): #指定拡張子の画像をループ
if fn.lower().endswith(('.png','.jpg','.jpeg','.tif','.JPEG')):
path_in = os.path.join(in_dir, fn)
path_out = os.path.join(out_dir, fn)
path_crop = os.path.join(out_dir, "crop_"+fn)
img = cv2.imread(path_in) #画像読み込み
if img is None:
print(f"{fn} 読み込み失敗")
continue
img_boxed, crop_img = detect_and_extract_color_scale(img) #カラースケール検出・抽出
cv2.imwrite(path_out, img_boxed) #元画像へ枠描画したものを保存
print(f"{fn} に枠を描画")
if crop_img is not None:
cv2.imwrite(path_crop, crop_img) #抽出したカラースケール画像も保存
print(f"{fn} の切り出し領域を保存")
if __name__ == "__main__":
process_images(INPUT_DIR, OUTPUT_DIR) #メインとして実行時、定義したフォルダ内のすべての画像を一括処理する
このスクリプトは「ドローン画像」フォルダ内の画像ファイルを処理し特定のカラースケールを自動抽出・保存するもので、画像分類やサンプル収集, データ前処理の自動化に有用な構造となっている。
import cv2
import numpy as np
import os
import shutil
INPUT_DIR = "processed_patches1"
OUTPUT_DIR = "processed_patches2"
MATRIX_DIR = "processed_patches2"
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs(MATRIX_DIR, exist_ok=True)
folder_name = OUTPUT_DIR
if os.path.exists(folder_name):
shutil.rmtree(folder_name)
print(f"既存のフォルダ '{folder_name}' を削除しました。")
os.makedirs(folder_name, exist_ok=True)
print(f"新しいフォルダ '{folder_name}' を作成しました。")
# 純色BGR値(OpenCVはBGR順)
pure_colors = [ #画像上の標準「ターゲット純色」BGR値
(0, 0, 255), # 赤
(0, 255, 255), # 黄
(0, 255, 0), # 緑
(255, 0, 0) # 青
]
def create_color_conversion_matrix(img): #入力画像を4分割し、それぞれの平均BGRとターゲット純色を記述した辞書をリストに格納
h, w = img.shape[:2] #高さ・幅を取得
conversion_matrix = []
if h > w:
# 縦長:縦方向に4分割(色ごとの帯が縦に配置されている前提)
segment_h = h // 4
for i in range(4):
region = img[i*segment_h:(i+1)*segment_h if i<3 else h, :]
avg_bgr = region.mean(axis=(0,1)) #各リージョンごとにregion.mean(axis=(0,1))平均色BGRを求めリスト化
conversion_matrix.append({
'segment': i,
'avg_bgr': avg_bgr,
'target_color': pure_colors[i]
})
else:
# 横長:横方向に4分割
segment_w = w // 4
# 横長は左から [青, 緑, 黄, 赤] のため色配列を逆順にする
reversed_colors = pure_colors[::-1]
for i in range(4):
region = img[:, i*segment_w:(i+1)*segment_w if i<3 else w]
avg_bgr = region.mean(axis=(0,1))
conversion_matrix.append({
'segment': i,
'avg_bgr': avg_bgr,
'target_color': reversed_colors[i]
})
return conversion_matrix
def save_conversion_matrix(matrix, filename): #np.save()でnpy形式保存
np.save(filename, matrix)
def apply_pure_colors(img, matrix): #入力画像と変換行列から全ピクセルを純色ターゲットで塗り替えたイメージ画像を生成
h, w = img.shape[:2] #区画ごとに指定色で塗り分ける
result = np.zeros_like(img)
if h > w:
# 縦長:縦方向に4分割
segment_h = h // 4
for entry in matrix:
i = entry['segment']
color = entry['target_color']
start_y = i * segment_h
end_y = (i + 1) * segment_h if i < 3 else h
result[start_y:end_y, :] = color
else:
# 横長:横方向に4分割
segment_w = w // 4
for entry in matrix:
i = entry['segment']
color = entry['target_color']
start_x = i * segment_w
end_x = (i + 1) * segment_w if i < 3 else w
result[:, start_x:end_x] = color
return result
#指定ディレクトリ内の全画像を処理
#ファイルごとに読込→変換行列作成・保存→純色置換画像生成→保存の流れ
#例外処理も加味
def process_images(input_dir, output_dir, matrix_dir):
for fn in os.listdir(input_dir):
if not fn.lower().endswith(('.png','.jpg','.jpeg','.tif','.JPEG')):
continue
path_in = os.path.join(input_dir, fn)
img = cv2.imread(path_in)
if img is None:
print(f"{fn} 読み込み失敗")
continue
matrix = create_color_conversion_matrix(img)
# 拡張子なしのファイル名を取得
base_name = os.path.splitext(fn)[0]
# .npy保存時には拡張子なしファイル名にする
save_path = os.path.join(matrix_dir, base_name + ".npy")
save_conversion_matrix(matrix, save_path)
pure_img = apply_pure_colors(img, matrix)
path_out = os.path.join(output_dir, fn)
cv2.imwrite(path_out, pure_img)
print(f"{fn} 処理完了:変換行列保存と純色画像保存")
if __name__ == "__main__":
process_images(INPUT_DIR, OUTPUT_DIR, MATRIX_DIR) #メインで呼出すことで処理スタート
このスクリプトは抽出したカラースケール画像の各色領域の平均値を求め、「赤・黄・緑・青」の純色に変換するための処理とその変換行列(マトリクス)の保存を行う。
-なぜ色補正に「黄色」を加えたか
→多くの画像処理・印刷系カラースケールやカラーチャートでは、赤・緑・青(RGB)だけでなく「黄色」も大変重要な指標色として含まれている。
・黄色は「赤+緑」成分が強調された複合色であり、RGBチャネルだけでは補正しきれない場合や印刷インクやセンサ特性の実用色域を反映するため。
・実際のカメラ画像やプリンタ特性, スキャナ入力の現場では、黄方向専用のズレや退色などが発生しやすくこれを補正しないと正確なカラーマッピングができない場合が多い。
・黄色チャネルの平均値を併せて色補正に参入することで、「中間色での精度維持」や「RGBのみでは表現できない偏りの補正」が可能に。
つまり「赤・緑・青」に加えて「黄」も参照することで現実的なタイミング補正やカメラの色再現性を大きく高めることができるため、より正確な色補正を実現するために黄色チャネルも加えることが必要と考えた。
import cv2
import numpy as np
import os
import shutil
# === 設定 ===
SCALE_DIR = "processed_patches2" # カラースケール抽出済み(crop付き)
INPUT_DIR = "drone_images" # 元画像フォルダ
OUTPUT_DIR = "processed_patches3" # 補正後出力フォルダ
# 出力フォルダを初期化
if os.path.exists(OUTPUT_DIR):
shutil.rmtree(OUTPUT_DIR)
os.makedirs(OUTPUT_DIR, exist_ok=True)
print(f"🗂️ 出力フォルダを作成: {OUTPUT_DIR}")
# === 理想の純色(RGB順) ===
PURE_RGB = np.array([ # 赤、黄、緑、青、それぞれの理想的なRGB値を定義(上から順に対応)
[255, 0, 0], # 赤
[255, 255, 0], # 黄
[0, 255, 0], # 緑
[0, 0, 255] # 青
], dtype=np.float32)
# === カラースケールの4色平均を取得 ===
#画像が縦長なら上→下に赤→黄→緑→青、横長なら左→右で青→緑→黄→赤
#各区画ごとにピクセル平均を計算し、BGR→RGB順に並べてリスト化
#横長時は配列の順番を赤→黄→緑→青のRGB順に修正
def extract_scale_colors(scale_img):
"""カラースケール画像から4色の平均色(RGB順)を抽出"""
h, w = scale_img.shape[:2]
vertical = h > w
colors = []
if vertical:
# 縦長: 上から 赤→黄→緑→青
step = h // 4
for i in range(4):
region = scale_img[i*step:(i+1)*step if i<3 else h, :]
avg_bgr = region.mean(axis=(0,1))
avg_rgb = avg_bgr[::-1] # BGR→RGB
colors.append(avg_rgb)
else:
# 横長: 左から 青→緑→黄→赤
step = w // 4
for i in range(4):
region = scale_img[:, i*step:(i+1)*step if i<3 else w]
avg_bgr = region.mean(axis=(0,1))
avg_rgb = avg_bgr[::-1]
colors.append(avg_rgb)
# 横長は順序を赤→黄→緑→青に直す
colors = [colors[3], colors[2], colors[1], colors[0]]
return np.array(colors, dtype=np.float32)
# === 変換行列の計算 ===
#緑パッチの誤差を重視するために重み配列を生成
#観測色から理想色への変換を重み付き最小二乗法(線形)で算出
def weighted_least_squares_matrix(observed, pure, green_weight): # サンプルごとに重み配列を作成
weights = np.ones(4)
weights[2] = green_weight
W = np.diag(weights) # 重み付き最小二乗: (O^T W O)x = O^T W P
A = np.linalg.solve(observed.T @ W @ observed, observed.T @ W @ pure)
return A
# === 行列適用 ===
# 多項式補正関数(RGB各チャンネルに2次多項式)
#RGB各チャンネルに対し2次多項式補正(明るさ非線形)を加える
def polynomial_correction(rgb_flat, coeffs):
corrected = np.zeros_like(rgb_flat)
for c in range(3):
a, b, c0 = coeffs[c]
corrected[:, c] = a * (rgb_flat[:, c]**2) + b * rgb_flat[:, c] + c0
return corrected
# 行列適用+多項式+ガンマ補正
def apply_matrix(img, M, rgb_strength=(1.0, 0.7, 1.0), gamma=(1.0,1.0,1.0), poly_coeffs=[(0,1,0), (0,1,0), (0,1,0)]):
"""
#入力画像をRGB変換→行列線形補正→強度倍率補正(チャンネル別)→多項式補正→ガンマ補正、の順に適用して最終画像を返す
#img: 入力画像(BGR)
#M: 3x3変換行列
#rgb_strength: チャンネル毎の乗算強度
#gamma: チャンネル毎のガンマ補正値(べき乗の逆数をかける)
#poly_coeffs: 各チャンネルの多項式係数(a,b,c)のリスト
"""
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB).astype(np.float32)
h, w = img_rgb.shape[:2]
flat = img_rgb.reshape(-1, 3)
# 線形変換
corrected_flat = np.dot(flat, M)
# 強度補正
for c in range(3):
corrected_flat[:, c] *= rgb_strength[c]
# 多項式補正
corrected_flat = polynomial_correction(corrected_flat, poly_coeffs)
# ガンマ補正(正規化してべき乗)
for c in range(3):
# 0-255範囲を0-1に変換して補正、戻す
corrected_flat[:, c] = np.power(np.clip(corrected_flat[:, c]/255.0, 0, 1), 1.0 / gamma[c]) * 255.0
corrected_flat = np.clip(corrected_flat, 0, 255).astype(np.uint8)
corrected = corrected_flat.reshape(h, w, 3)
return cv2.cvtColor(corrected, cv2.COLOR_RGB2BGR)
# === 誤差評価関数 ===
#4色の各パッチに対し、色差誤差を計算して合計
#とくに緑のB・R、赤のG・B、黄のR、青のG・Bの項目で誤差を合算
def multi_patch_error(observed, pure, M, rgb_strength):
pred = np.dot(observed, M)
for i in range(4):
pred[i, 0] *= rgb_strength[0] # 赤
pred[i, 1] *= rgb_strength[1] # 緑
pred[i, 2] *= rgb_strength[2] # 青
e_red_G = np.abs(pred[0, 1] - 0)
e_red_B = np.abs(pred[0, 2] - 0)
e_yellow_R = np.abs(pred[1,0] - 255)
e_green_R = np.abs(pred[2, 0] - 0)
e_green_B = np.abs(pred[2, 2] - 0)
e_blue_G = np.abs(pred[3, 1] - 0)
e_blue_B = np.abs(pred[3, 2] - 255)
error_total = e_green_B + e_green_R + e_red_G + e_red_B + e_blue_B + e_blue_G + e_yellow_R
return error_total
best_params = None
best_err = float('inf')
"""
# グリッド探索範囲
#グリッド探索範囲として、緑重み・RGB倍率の候補群を用意。
#最初の元画像1枚のパッチを観測値とし、
#全ての候補パラメータで「変換→誤差評価」
#最良パラメータを採用(loop脱出)。
#採用パラメータを表示。
"""
green_weights = np.arange(5, 81, 1) # "5"から"80"まで"1"刻みで探索
red_values = np.arange(1.2, 1.3, 0.1) # 1.2固定
green_values = np.arange(1.3, 1.4, 0.1) # 1.3固定
blue_values = np.arange(1.2, 1.3, 0.1) # 1.2固定
# カラースケール画像1枚目だけでパラメータ探索
for fn in os.listdir(INPUT_DIR):
if not fn.lower().endswith((".jpg", ".jpeg", ".png",'.tif','.JPEG')):
continue
base = os.path.splitext(fn)[0]
scale_path = os.path.join(SCALE_DIR, f"crop_{base}.jpg")
if not os.path.exists(scale_path):
continue
scale_img = cv2.imread(scale_path)
observed = extract_scale_colors(scale_img)
pure = PURE_RGB.copy()
for gw in green_weights:
for rv in red_values:
for gv in green_values:
for bv in blue_values:
rgb_strength = (rv, gv, bv)
M = weighted_least_squares_matrix(observed, pure, gw)
err = multi_patch_error(observed, pure, M, rgb_strength)
if err < best_err:
best_err = err
best_params = dict(gw=gw, rv=rv, gv=gv, bv=bv, M=M, rgb_strength=rgb_strength)
break
print(f"⭐ 最良パラメータ: weight={best_params['gw']}, rgb={best_params['rgb_strength']}")
M = best_params["M"]
rgb_strength = best_params["rgb_strength"]
# 画像全体に最適化後の補正を適用
#フォルダ内の全画像を対象にスケールパッチ画像を抽出し補正式で色補正
#結果を出力フォルダに保存し進捗を通知
for fn in os.listdir(INPUT_DIR):
if not fn.lower().endswith((".jpg", ".jpeg", ".png",'.tif','.JPEG')):
continue
base = os.path.splitext(fn)[0]
scale_path = os.path.join(SCALE_DIR, f"crop_{base}.jpg")
img_path = os.path.join(INPUT_DIR, fn)
out_path = os.path.join(OUTPUT_DIR, fn)
if not os.path.exists(scale_path):
print(f"⚠️ カラースケールが見つかりません: {fn} → スキップ")
continue
scale_img = cv2.imread(scale_path)
observed = extract_scale_colors(scale_img)
pure = PURE_RGB.copy()
corrected = apply_matrix(cv2.imread(img_path), M, rgb_strength)
cv2.imwrite(out_path, corrected)
print(f"✅ 補正完了: {fn} → {out_path}")
print("\n🎯 全画像の色補正が完了しました。")
スクリプト前半で画像からカラースケール領域の抽出と各色の平均値を計算を行い、理想的な純色(赤・黄・緑・青)との差を最小化するように行列と補正関数をチューニングし、自動で最良の補正式を決定
重要な補正式として「緑帯の誤差を重視」する重み調整ロジックがあるが、これは植物判別や野外画像用途など彩度管理でよく使われる手法である
画像から特定パッチを切り出し平均RGB値を計算し、その値と理想カラーチャート(赤・黄・緑・青)をマッチング
複数の補正パラメータ(行列、強度、ガンマなど)を探索し、4色全体の誤差を最小化するものを一括自動選定 選ばれた補正式で全データを統一的に補正
◯プレート領域の白枠マスク・抽出スクリプト 基本設定・フォルダ操作 入出力フォルダ名などの初期設定 既存の出力先は削除し、新たに作り直します プレート領域のマスク処理 mask_plate_regionで画像をグレースケール化して白黒マスク像を生成し、白枠が主領域となるように反転処理 ◯ノイズ除去(remove_noise) 細かな領域や切れぎみの線の補完を行った後に小面積のゴミ除去(connectedComponentsWithStats利用)し輪郭抽出・検証・手 動で4点を指定する ◯輪郭取得(detect_plate_contour) 画像から白枠(矩形状)の輪郭を検出し、面積・中心・角度・アスペクト比などで厳しくフィルタ 基準に適合しない場合はGUIでユーザー4点指定もサポート
import cv2
import numpy as np
import os
import shutil
from glob import glob
# === 設定 ===
INPUT_DIR = "processed_patches3" # 入力画像フォルダ
OUTPUT_DIR = "processed_patches4" # 出力フォルダ
REF_WIDTH = 1000 # 出力画像の横サイズ
REF_HEIGHT = 750 # 出力画像の縦サイズ
os.makedirs(OUTPUT_DIR, exist_ok=True)
# === フォルダーの削除・作成 ===
folder_name = OUTPUT_DIR
if os.path.exists(folder_name):
shutil.rmtree(folder_name)
print(f"既存のフォルダ '{folder_name}' を削除しました。")
os.makedirs(folder_name, exist_ok=True)
print(f"新しいフォルダ '{folder_name}' を作成しました。")
# === 1. プレート領域のマスク処理 ===
def mask_plate_region(img, threshold_mode="adaptive"): #★
"""
撮影画像から白いプレート枠領域を抽出してマスク化する。
"""
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (7, 7), 0) #★
if threshold_mode == "otsu":
_, binary = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
elif threshold_mode == "adaptive":
binary = cv2.adaptiveThreshold(blur, 255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 15, 4) #★
else:
raise ValueError("threshold_mode must be 'otsu' or 'adaptive'")
# 白黒反転(白枠が白くなるように)
if np.mean(binary) < 127:
binary = cv2.bitwise_not(binary)
return binary
# === 2. ノイズ除去処理 ===
def remove_noise(binary_mask):
"""
二値化画像から小さなノイズを除去し、白枠を明確化する。
"""
kernel = np.ones((4, 4), np.uint8) #★
# Opening:白ノイズ除去
opened = cv2.morphologyEx(binary_mask, cv2.MORPH_OPEN, kernel, iterations=2) #★
# Closing:枠線の途切れ補完
closed = cv2.morphologyEx(opened, cv2.MORPH_CLOSE, kernel, iterations=2) #★
# Connected Componentで小領域除去
num_labels, labels, stats, _ = cv2.connectedComponentsWithStats(closed)
cleaned = np.zeros_like(closed)
for i in range(1, num_labels): # 0は背景
area = stats[i, cv2.CC_STAT_AREA]
if area > 500: #★
cleaned[labels == i] = 255
return cleaned
# === 3. 輪郭の取得と近似化 ===
def detect_plate_contour(img, cleaned_mask):
"""
白枠プレートの輪郭を検出し、内側スケール矩形のみを抽出。
外枠(画像外周)は無視。
条件:
- 面積が 20000〜1450×1060 の範囲
- アスペクト比が 1.0〜a の範囲
- 図形中心が画像の外周b%以内でない
- 各角の角度が c°〜d° の範囲
"""
h, w = img.shape[:2]
max_allowed_area = 1450 * 1060
min_allowed_area = 630 * 340
# --- ① 外枠除外マスク ---
inner_mask = np.zeros_like(cleaned_mask)
margin = int(min(h, w) * 0.12) # 外周を無視
inner_mask[margin:h - margin, margin:w - margin] = 255
masked = cv2.bitwise_and(cleaned_mask, inner_mask)
# --- ② 輪郭検出 ---
contours, _ = cv2.findContours(masked, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if not contours:
print("⚠️ 輪郭が検出されませんでした。")
return img, None
valid_candidates = []
for cnt in contours:
area = cv2.contourArea(cnt)
if area < min_allowed_area or area > max_allowed_area:
continue
rect = cv2.minAreaRect(cnt)
(cx, cy), (rw, rh), angle = rect
# --- ③ 中心位置チェック(外周に寄りすぎていないか) ---
if cx < margin or cx > (w - margin) or cy < margin or cy > (h - margin):
continue
# --- ④ アスペクト比チェック ---
aspect_ratio = max(rw, rh) / (min(rw, rh) + 1e-6)
if not (1.5 <= aspect_ratio <= 2.0):
continue
# --- ⑤ 近似と角度判定 ---
epsilon = 0.02 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
if len(approx) != 4:
continue
pts = approx.reshape(4, 2)
angles = []
for i in range(4):
p1, p2, p3 = pts[i], pts[(i + 1) % 4], pts[(i + 2) % 4]
v1, v2 = p1 - p2, p3 - p2
cos_angle = np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2) + 1e-6)
angle = np.degrees(np.arccos(np.clip(cos_angle, -1.0, 1.0)))
angles.append(angle)
if all(69 <= a <= 111 for a in angles):
valid_candidates.append((area, pts))
# --- ⑥ 最も適した候補を選択 ---
if not valid_candidates:
print("⚠️ 有効な内枠が見つかりませんでした。手動で4点を選択してください。")
manual_points = []
def mouse_callback(event, x, y, flags, param):
if event == cv2.EVENT_RBUTTONDOWN: # 右クリックで追加
manual_points.append((x, y))
cv2.drawMarker(param, (x, y), (0, 255, 0), cv2.MARKER_TILTED_CROSS, 20, 2)
cv2.imshow("manual_select", param)
print(f"✅ 追加: {len(manual_points)}点目 ({x}, {y})")
elif event == cv2.EVENT_LBUTTONDOWN: # 左クリックでキャンセル
if manual_points:
manual_points.pop()
print(f"↩️ 直前の点を削除。残り {len(manual_points)} 点。")
param_copy = img.copy()
for px, py in manual_points:
cv2.drawMarker(param_copy, (px, py), (0, 255, 0), cv2.MARKER_TILTED_CROSS, 20, 2)
cv2.imshow("manual_select", param_copy)
temp = img.copy()
cv2.imshow("manual_select", temp)
cv2.setMouseCallback("manual_select", mouse_callback, temp)
print("🖱️ 右クリックで4点選択、左クリックで直前をキャンセル。完了後に Enter を押してください。")
while True:
key = cv2.waitKey(0)
if key in [13, 10]: # Enter
break
cv2.destroyWindow("manual_select")
if len(manual_points) != 4:
print("⚠️ 4点が選択されませんでした。スキップします。")
return img, None
best_pts = np.array(manual_points, dtype=np.float32)
contour_img = img.copy()
cv2.polylines(contour_img, [best_pts.astype(int)], isClosed=True, color=(0, 255, 0), thickness=3)
print("✅ 手動で内枠を確定しました。")
return contour_img, best_pts
best_area, best_pts = max(valid_candidates, key=lambda x: x[0])
contour_img = img.copy()
cv2.drawContours(contour_img, [best_pts.astype(int)], -1, (0, 255, 0), 4)
print(f"🟩 内枠矩形を検出(面積={best_area:.0f}, アスペクト比={aspect_ratio:.2f})")
return contour_img, best_pts
# === 4. メイン処理 ===
for fname in os.listdir(INPUT_DIR):
if not fname.lower().endswith((".jpg", ".jpeg", ".png")):
continue
img_path = os.path.join(INPUT_DIR, fname)
img = cv2.imread(img_path)
if img is None:
print(f"⚠️ 読み込み失敗: {fname}")
continue
# --- ステップ1: マスク化 ---
mask = mask_plate_region(img, threshold_mode="otsu")
2. 緑枠検出と台形補正 ○基本設定 台形補正に使う出力画像サイズ、検出用緑範囲、フォルダ再初期化 ○緑枠検出(detect_green_corners) BGR→HSV変換し、緑色HSV域をinRangeで抽出 輪郭検出し、最大4点近似で「緑枠」四隅座標を取得 ○透視変換による補正(perspective_correction) 4点座標を「左上→右上→右下→左下」に順序付け 指定したサイズに合わせてOpenCVの透視変換実行
import cv2
import numpy as np
import os
import shutil
# === 設定 ===
INPUT_DIR = "processed_patches4" # 緑枠付き画像フォルダ
OUTPUT_DIR = "processed_patches5" # 台形補正後の出力フォルダ
os.makedirs(OUTPUT_DIR, exist_ok=True)
# === 出力画像サイズ ===
# 縦8cm × 横14cm → 比率4:7 として例: 256×448 ピクセルに統一
OUT_H, OUT_W = 256, 448
# === 緑色検出用のHSV範囲(調整可能) ===
HSV_LOWER = np.array([35, 80, 40]) # 緑の下限
HSV_UPPER = np.array([85, 255, 255]) # 緑の上限
# === フォルダ初期化 ===
if os.path.exists(OUTPUT_DIR):
shutil.rmtree(OUTPUT_DIR)
print(f"🧹 既存のフォルダ '{OUTPUT_DIR}' を削除しました。")
os.makedirs(OUTPUT_DIR, exist_ok=True)
print(f"📁 新しいフォルダ '{OUTPUT_DIR}' を作成しました。")
def detect_green_corners(img):
"""
緑枠の四隅を検出して返す。
成功すれば4点座標(np.float32)を返し、失敗時はNone。
"""
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv, HSV_LOWER, HSV_UPPER)
# ノイズ除去
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5))
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel, iterations=1)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel, iterations=2)
# 輪郭検出
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if not contours:
return None
# 面積の大きい順にソート
contours = sorted(contours, key=cv2.contourArea, reverse=True)
for cnt in contours:
peri = cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, 0.04 * peri, True)
if len(approx) == 4:
pts = approx.reshape(4, 2).astype(np.float32)
return pts # 四角形と認識されたら返す
return None
def order_points(pts):
"""4点を順序付きに整列(左上・右上・右下・左下)"""
rect = np.zeros((4, 2), dtype="float32")
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)] # 左上
rect[2] = pts[np.argmax(s)] # 右下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)] # 右上
rect[3] = pts[np.argmax(diff)] # 左下
return rect
def perspective_correction(img, pts, out_size=(OUT_W, OUT_H)):
"""透視変換を行い、指定サイズにリサイズ"""
rect = order_points(pts)
dst = np.array([
[0, 0],
[out_size[0] - 1, 0],
[out_size[0] - 1, out_size[1] - 1],
[0, out_size[1] - 1]
], dtype="float32")
# dst の順番 (w,h)に注意:OpenCVでは横×縦
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(img, M, out_size)
return warped
# === メイン処理 ===
for fname in os.listdir(INPUT_DIR):
if not fname.lower().endswith((".jpg", ".jpeg", ".png")):
continue
path_in = os.path.join(INPUT_DIR, fname)
img = cv2.imread(path_in)
if img is None:
print(f"⚠️ 画像読み込み失敗: {fname}")
continue
corners = detect_green_corners(img)
if corners is None:
print(f"⚠️ 緑枠の四隅が検出できません: {fname}")
continue
warped = perspective_correction(img, corners, out_size=(OUT_W, OUT_H))
path_out = os.path.join(OUTPUT_DIR, fname)
cv2.imwrite(path_out, warped)
print(f"✅ {fname} を補正・保存しました。")
print(f"\n🎯 台形補正が完了しました。出力フォルダ: {OUTPUT_DIR}")
○基本設定
目的ごとのフォルダ/クロップ範囲等を準備
○自動クロップ
各入力画像を一定サイズ(例:256x256)でNUM_CROPS枚だけ切り抜き、オーバーラップ比率を調整しながらスライド
保存ファイル名は評価点+連番で命名
import cv2
import os
import numpy as np
import shutil
# === 設定 ===
INPUT_DIR = "processed_patches5" # 抽出済み錆画像フォルダ
OUTPUT_DIR = "processed_patches6" # 出力先
CROP_SIZE = 256 # 切り抜きサイズ(px)
NUM_CROPS = 4 # 1枚あたり生成枚数
OVERLAP_RATIO = 0.3 # オーバーラップ率(0.0〜0.9)
# === 出力フォルダ初期化 ===
if os.path.exists(OUTPUT_DIR):
shutil.rmtree(OUTPUT_DIR)
os.makedirs(OUTPUT_DIR, exist_ok=True)
print(f"🗂️ 出力フォルダを作成: {OUTPUT_DIR}")
# === メイン処理 ===
for fname in os.listdir(INPUT_DIR):
if not fname.lower().endswith((".jpg", ".jpeg", ".png")):
continue
# 元画像の評点(例: "1S_0001.jpg" → score = 1)
score = fname[0]
img_path = os.path.join(INPUT_DIR, fname)
img = cv2.imread(img_path)
if img is None:
print(f"⚠️ 読み込み失敗: {fname}")
continue
h, w = img.shape[:2]
# 切り抜き可能数を超える場合は調整
crop_w = CROP_SIZE
crop_h = CROP_SIZE
# オーバーラップを考慮して切り抜き開始座標を決定
x_step = int((w - crop_w) / (NUM_CROPS - 1)) if NUM_CROPS > 1 else 0
y_step = int((h - crop_h) / (NUM_CROPS - 1)) if NUM_CROPS > 1 else 0
# オーバーラップの設定(比率で調整)
x_step = max(int(crop_w * (1 - OVERLAP_RATIO)), 1)
y_step = max(int(crop_h * (1 - OVERLAP_RATIO)), 1)
# スライドウィンドウ的に切り抜き
crop_count = 0
for y in range(0, max(h - crop_h + 1, 1), y_step):
for x in range(0, max(w - crop_w + 1, 1), x_step):
crop = img[y:y+crop_h, x:x+crop_w]
if crop.shape[0] != CROP_SIZE or crop.shape[1] != CROP_SIZE:
continue
crop_count += 1
save_name = f"{score}_{crop_count}.jpg"
save_path = os.path.join(OUTPUT_DIR, save_name)
cv2.imwrite(save_path, crop)
if crop_count >= NUM_CROPS:
break
if crop_count >= NUM_CROPS:
break
print(f"✅ {fname}: {crop_count}枚の256×256画像を生成")
print("🎯 全画像の切り抜き完了。")
カラーの錆画像を256ピクセル四方で切り抜くことができた。11日以降にCNNで学習させていきたいと思っている。








































抽出の際に使用した緑の枠が残ってしまっているがとりあえずこのまま学習にかけてみて、もし上手く行かないのであれば取り除くといった方向性で考えている。
錆画像スキャン方法 ・スキャナーは研究室にあるものを使用する ・使用するソフトはXSane(デスクトップの左上 "メニュー → すべて → XSane")
創造工房実習でI型断面等の三角形分布や塑性状態がどういう応力分布になっているのかを確認するのを忘れていたのでここに書いておく。

上端
・ーーーーーーーーーー
| ーーーーー
・ーーーーーーーーー ーーーー|
下端 ーーーーー |↓集中荷重位置 このように上端ー集中荷重位置の距離が下端よりも長いことから上端側のほうが直応力が大きい。
ーーーーー| 逆方向に面載荷をかければ下端側の直応力が大きくなるだろう。
1ステップごとに面に載荷した荷重の10分の1を加えたものーDEPLとのグラフを作成
| 経過時間 | ↖たわみ(mm) | ↖応力(MPa) | ↗たわみ(mm) | ↗応力(MPa) |
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0.000140332 | 34.4925 | 0.000184238 | 44.0832 |
| 2 | 0.000280661 | 68.9829 | 0.000368391 | 88.1643 |
| 3 | 0.000420986 | 103.471 | 0.000552457 | 132.243 |
| 4 | 0.000561308 | 137.957 | 0.000736434 | 176.318 |
| 5 | 0.000701624 | 172.44 | 0.000923909 | 220.147 |
| 6 | 0.000842636 | 206.506 | 0.00123269 | 241.658 |
| 7 | 0.00101987 | 237.23 | 0.002051 | 244.44 |
| 8 | 0.00130101 | 257.808 | 0.00765896 | 243.452 |
| 9 | 0.00191133 | 268.432 | 0.0109555 | 241.582 |
| 10 | 0.00377436 | 280.533 | 0.0148525 | 239.658 |
| 11 | ー | ー | 0.0191575 | 237.724 |
| 12 | ー | ー | 0.0237442 | 235.762 |
| 13 | ー | ー | 0.0285207 | 233.804 |
| 14 | ー | ー | 0.0333983 | 231.819 |
| 15 | ー | ー | 0.0383132 | 229.768 |
| 16 | ー | ー | 0.043212 | 227.625 |
⇒一度01と入力しOKを押した後再度1.0と入力する画面に戻ると小数点を入力できるようになっている。
⇒原因は関数がある範囲までしか定義されていないの事。Function and ListsのDEFI_FONCTIONにおいて関数の外側も定義できるようにCONSTANTまたはLINEARを追加しておく必要がある。
春休みの課題
今日はviを用いて論文に画像を貼る方法について学んだ。
今日はviを用いた論文の書き方を学んだ。
・文頭に%をつけるとその行に書かれた文章は反映されない
・強制改行したい場合は"\\"を入力する
・更新→:!pdfplatexsibup2
○式を書く(書き方は編集画面から)
\( v=\frac{P\ell^{3}}{48EI} + \frac{P\ell}{4kGA} \)
今回は鋼材で木材を挟んだサンドイッチ梁の解析を行い、縦軸に変位(mm), 横軸にボリューム数をとって上のグラフを作成した。 メッシュ長さの大小関係なく理論値と20%の誤差が生じ、これ以上メッシュ長さを短くしても理論値には近づくことがないと推測する。サンドイッチ梁は多分見たことがない以上イメージが湧かず誤差の推測をしようがないので実物にこの目で見て実験を行いたい。今回は鋼材で木材を挟んだサンドイッチ梁を解析したが、実用性を一旦置いて木材で鋼材を挟んだサンドイッチ梁の場合結果はどうなるのだろうか。
全員で作成した解析結果のグラフを下に示しておく
| メッシュ長さ | 要素数 | 先端変位(4隅の平均値)[mm] | 相対誤差(\( \frac{salome-手計算}{手計算} \)) | 計算者 |
| 0.7 | 155419 | 0.0772 | 26.943 | 湊 |
| 0.8 | 138734 | 0.0775 | 26.452 | 湊 |
| 0.9 | 82935 | 0.0774 | 26.614 | 湊 |
| 1.1 | 38671 | 0.0766 | 27.937 | 森井 |
| 1.2 | 32044 | 0.0770 | 27.273 | 森井 |
| 1.3 | 28599 | 0.0768 | 27.604 | 森井 |
| 1.4 | 23950 | 0.07640 | 22.04 | 米谷 |
| 1.5 | 19998 | 0.07641 | 22.03 | 米谷 |
| 1.6 | 19448 | 0.07715 | 21.28 | 米谷 |
| 1.7 | 13801 | 0.07567 | 22.79 | 米谷 |
| 1.8 | 12677 | 0.07736 | 21.06 | 沼野 |
| 1.9 | 11464 | 0.07546 | 23.00 | 沼野 |
| 2 | 10699 | 0.07404 | 24.45 | 沼野 |
| 3 | 3579 | 0.08414 | 15.004 | 國井 |
| 4 | 1628 | 0.08279 | 16.37 | 國井 |
| 5 | 1016 | 0.08303 | 16.26 | 國井 |
| 6 | 839 | 0.08288 | 16.26 | 西澤 |
| 7 | 554 | 0.08087 | 18.28 | 西澤 |
| 8 | 285 | 0.07898 | 19.20 | 西澤 |
| 9 | 261 | 0.01421 | 85.49 | 真庭 |
| 10 | 232 | 0.03380 | 65.51 | 真庭 |
| 11 | 208 | 0.00913 | 90.68 | 真庭 |
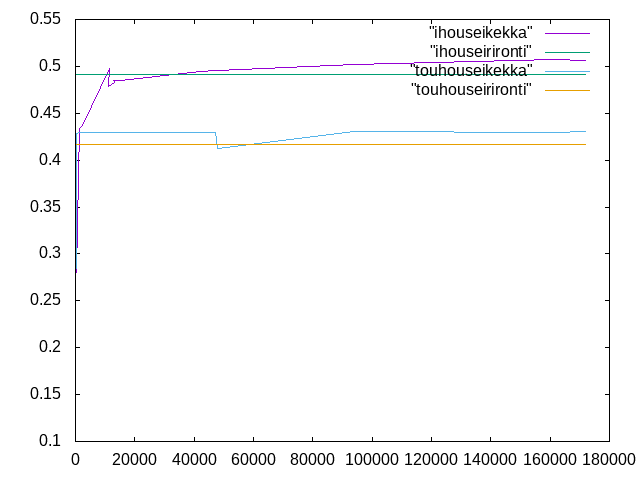
今回は単純異方性と等方性の解析を行い、縦軸に変位(mm), 横軸にボリューム数をとって上のグラフを作成した。異方性は上2つのグラフであるが、メッシュ長さを2以下で解析を行うと理論値(緑)と近しい値をとるようになる。一方で等方性の場合はメッシュ長さが5までなら理論値と似たような値をとる結果となった。前回まではメッシュを細かくするほど理論値に近づいたが異方性の場合はメッシュ長さを1.3にした時が理論値に一番近づき、等方性の場合は理論値と平行関係になってしまった。さらに長さを小さくして解析しても理論値には近づくことがないのではないか。
全員で作成した解析結果のグラフを下に示しておく
| メッシュ長さ | 要素数 | 変位(異方性)[mm] | 相対誤差-異方性(\( \frac{salome-手計算}{手計算} \)) | 変位(等方性)[mm] | 相対誤差-等方性(\( \frac{salome-手計算}{手計算} \)) | 計算者 |
| 0.7 | 171996 | 0.5068 | 2.993 | 0.4301 | 3.141 | 湊 |
| 0.8 | 161561 | 0.5069 | 2.999 | 0.4300 | 3.116 | 湊 |
| 0.9 | 94185 | 0.5021 | 2.071 | 0.4301 | 3.139 | 湊 |
| 1.1 | 47998 | 0.4957 | 0.814 | 0.4122 | 1.056 | 森井 |
| 1.2 | 47343 | 0.4952 | 0.712 | 0.4300 | 3.217 | 森井 |
| 1.3 | 42112 | 0.4941 | 0.488 | 0.4298 | 3.169 | 森井 |
| 1.4 | 38960 | 0.4937 | 0.407 | 0.4299 | 3.193 | 森井 |
| 1.5 | 15041 | 0.4845 | 1.460 | 0.4298 | 3.179 | 米谷 |
| 1.6 | 16071 | 0.4849 | 1.380 | 0.4298 | 3.157 | 米谷 |
| 1.7 | 12933 | 0.4845 | 1.460 | 0.4299 | 3.182 | 米谷 |
| 1.8 | 12993 | 0.4832 | 1.73 | 0.4298 | 3.19 | 沼野 |
| 1.9 | 11235 | 0.4783 | 2.73 | 0.4295 | 3.10 | 沼野 |
| 2 | 11456 | 0.4982 | 1.32 | 0.4296 | 3.12 | 沼野 |
| 3 | 2514 | 0.4369 | 4.87 | 0.4293 | 3.05 | 國井 |
| 4 | 1461 | 0.4341 | 4.20 | 0.4293 | 3.05 | 國井 |
| 5 | 433 | 0.2803 | 32.7 | 0.4284 | 2.83 | 國井 |
| 6 | 356 | 0.4283 | 2.80 | 0.3437 | 17.5 | 西澤 |
| 7 | 102 | 0.4260 | 2.26 | 0.2225 | 46.6 | 西澤 |
| 8 | 93 | 0.4260 | 2.26 | 0.1123 | 73.0 | 西澤 |
| 9 | 81 | 0.2212 | 54.9 | 0.4255 | 2.13 | 真庭 |
| 10 | 84 | 0.2051 | 58.3 | 0.4247 | 1.95 | 真庭 |
| 11 | 74 | 0.2260 | 54.0 | 0.4246 | 1.91 | 真庭 |
単純梁の解析結果から縦軸に変位(mm), 横軸にボリューム数をとって上のグラフを作成した。 前回と同じくメッシュの長さを長くすると接点変位は小さくなり、相対誤差は大きくなった。前回は√nに近い形のグラフが描けた一方で今回は歪な形のグラフができてしまった。変曲点はメッシュ数が小さい(1メッシュあたりの長さを長くした)方もといグラフ左側に偏っており、メッシュ長さを長くして解析を行うほど解析結果の信憑性は低くなるのではないか。他のPCと同じ解析を行った場合結果は一緒になるのだろうか?機会があればやってみたいものだ。
全員で作成した解析結果のグラフを下に示しておく
| メッシュ長さ | 要素数 | 先端変位(4隅の平均値)[mm] | 相対誤差(\( \frac{salome-手計算}{手計算} \)) | 計算者 |
| 0.7 | 171996 | 0.4260 | 2.207 | 湊 |
| 0.8 | 161561 | 0.4256 | 2.115 | 湊 |
| 0.9 | 94185 | 0.4169 | 0.0719 | 湊 |
| 1.1 | 47998 | 0.4122 | 1.067 | 森井 |
| 1.2 | 47343 | 0.4118 | 1.166 | 森井 |
| 1.3 | 42112 | 0.4113 | 1.289 | 森井 |
| 1.4 | 38960 | 0.4112 | 1.313 | 森井 |
| 1.5 | 15041 | 0.3978 | 4.516 | 米谷 |
| 1.6 | 16071 | 0.3999 | 4.002 | 米谷 |
| 1.7 | 12993 | 0.3971 | 4.687 | 米谷 |
| 1.8 | 12203 | 0.3964 | 4.85 | 沼野 |
| 1.9 | 11235 | 0.3942 | 5.38 | 沼野 |
| 2 | 11456 | 0.3991 | 4.20 | 沼野 |
| 3 | 2514 | 0.2141 | 21.4 | 國井 |
| 4 | 1461 | 0.34028 | 18.4 | 國井 |
| 5 | 433 | 0.1354 | 67.8 | 國井 |
| 6 | 356 | 0.2135 | 48.8 | 西澤 |
| 7 | 102 | 0.11 | 73.6 | 西澤 |
| 8 | 93 | 0.112 | 73.0 | 西澤 |
| 9 | 81 | 0.1125 | 73.0 | 真庭 |
| 10 | 84 | 0.0794 | 80.9 | 真庭 |
| 11 | 74 | 0.1297 | 68.9 | 真庭 |
全員で行った解析の結果を縦軸に変位, 横軸にボリューム数をとってグラフを作成した。 メッシュの長さを長くすると接点変位は小さくなり、相対誤差は大きくなった。 一方でメッシュの長さを小さくするほど接点変位は断面二次モーメントで算出された6.67mmに近づいた。 メッシュ長さを0.5や0.3として解析を行えばもっと理論値に値が近づくのではないか。
全員で作成した解析結果のグラフを下に示しておく
| メッシュ長さ | 要素数 | 先端変位(4隅の平均値)[mm] | 相対誤差(\( \frac{salome-手計算}{手計算} \)) | 計算者 |
| 0.7 | 107380 | 6.47 | 2.96 | 湊 |
| 0.8 | 57821 | 6.44 | 3.62 | 湊 |
| 0.9 | 57698 | 6.43 | 3.73 | 湊 |
| 1.1 | 57980 | 6.44 | 3.57 | 湊 |
| 1.2 | 52123 | 6.41 | 3.90 | 森井 |
| 1.3 | 45549 | 6.34 | 4.98 | 森井 |
| 1.4 | 26951 | 6.32 | 5.31 | 森井 |
| 1.5 | 16904 | 6.25 | 6.32 | 米谷 |
| 1.6 | 14296 | 6.20 | 7.05 | 米谷 |
| 1.7 | 13596 | 6.21 | 6.81 | 米谷 |
| 1.8 | 6299 | 5.74 | 13.9 | 沼野 |
| 1.9 | 6001 | 5.73 | 14.1 | 沼野 |
| 2 | 5617 | 5.65 | 15.3 | 沼野 |
| 3 | 2309 | 5.48 | 17.8 | 國井 |
| 4 | 617 | 3.62 | 45.6 | 國井 |
| 5 | 494 | 3.85 | 42.3 | 國井 |
| 6 | 581 | 2.51 | 62.4 | 西澤 |
| 7 | 133 | 1.41 | 78.8 | 西澤 |
| 8 | 78 | 1.29 | 80.7 | 西澤 |
| 9 | 72 | 1.288 | 80.69 | 真庭 |
| 10 | 60 | 1.226 | 81.62 | 真庭 |
| 11 | 65 | 1.231 | 81.54 | 真庭 |
今日(11/1)はwikiにグラフの貼り付けとviとlinuxを使ってグラフの作成を行った
上のグラフは自身で作成したもの、下のグラフは過去の先輩方が作成したグラフの数値を拝借した。
先輩方が作成したグラフの数値を下に示しておく
| メッシュの長さ | 要素数 | 変位[mm] | 相対誤差 | 計算者 |
| 0.7 | 155192 | 0.08378905246 | 15.365 | 安藤 |
| 0.8 | 138808 | 0.08380386491 | 15.350 | 安藤 |
| 0.9 | 82587 | 0.083707073981 | 15.45 | 兼田 |
| 1.1 | 38671 | 0.084201207602 | 14.95 | 兼田 |
| 1.2 | 31929 | 0.083688 | 15.466 | 柴田 |
| 1.3 | 28621 | 0.083669 | 15.4857 | 柴田 |
| 1.4 | 28854 | 0.08368 | 15.47 | 佐藤 |
| 1.5 | 20015 | 0.084052 | 15.10 | 佐藤 |
| 1.6 | 19448 | 0.0835402938 | 15.62 | 皆川 |
| 1.7 | 13801 | 0.0834355098 | 15.72 | 皆川 |
| 1.8 | 12528 | 0.083733 | 15.42 | 永山 |
| 1.9 | 11769 | 0.083924 | 15.23 | 永山 |
| 2 | 10699 | 0.084076876559 | 15.074 | 辻 |
| 3 | 3579 | 0.08414561753 | 15.004 | 辻 |
| 4 | 1628 | 0.082794 | 16.37 | 服部 |
| 5 | 1016 | 0.083033 | 18.89 | 服部 |
| 6 | 839 | 0.082882 | 16.26 | 梶原 |
| 7 | 554 | 0.080871 | 18.28 | 梶原 |
| 8 | 285 | 0.079995 | 19.20 | 工藤 |
| 9 | 261 | 0.078980 | 20.22 | 工藤 |
| 10 | 232 | 0.081911 | 17.26 | 佐々木 |
| 11 | 208 | 0.075676 | 23.56 | 佐々木 |
今日は顔合わせをした
頑張りたい "いきものがかり"についた