![[PukiWiki]](image/pukiwiki.png "[PukiWiki]")
丹羽の卒論日誌
https://www.str.ce.akita-u.ac.jp/~gotouhan/aono/a.txt
python3 -m venv .venv(最初のみ) source .venv/bin/activate ←仮想環境に入る これでpip installができる deactivate ←仮想環境から出るコマンドの表示と実行 →python:インタープリターを選択 →VSコードでも仮想環境に入ることができる
今回は5分割交差検証で行った.またepoch数は5とし,Repeat数は2回とした.
k-foldを導入した結果
http://www.str.ce.akita-u.ac.jp/~gotouhan/j2025/niwa/kfold_result1.txt
今回は試しで行ったためepoch数やRepeat数を少なくしている.したがって標準偏差は10.21と非常に大きく精度の信頼性はない.
次はepoch数10,Repeat数3でやってみる.
結果
http://www.str.ce.akita-u.ac.jp/~gotouhan/j2025/niwa/kfold_result2.txt
標準偏差も精度も悪くなってしまった.おそらく過学習が発生していると思われる.各Foldのlossを見ると途中からlossが増えているfoldがあったからである.
過学習が起きているかどうかを確かめるために,Validation Lossを導入し,train lossとtest lossを比較することでわかるようにした.また,epoch数,Repeat数はもとに戻した.
結果
http://www.str.ce.akita-u.ac.jp/~gotouhan/j2025/niwa/kfold_result3.txt
train loss は順調に少なくなっているのに,test loss は途中から増えていくFoldがあった.これは明らかに過学習の症状である.
今日から先輩から頂いた補正済みの橋梁の錆の近景データ267枚を使って評点を予測するモデルを作成していく.データ量が267枚しかないため,普通にいつもどおりにスクリプトを作成して正解率をだして行くと実行するたびに正解率が以上に高くなったり低くなったりと正解率自体の信憑性があまりない.また特に評点1と評点5のデータ数がそれぞれ6個ずつしかないため,評点1,5のせいか正解率は毎回非常に大きく変動してしまう.よってk-fold交差検証というものを導入した.
・k-fold交差検証を行うメリット:
・テストデータを様々なパターンで分けて行うので,精度の安定性が上がる.
・評価した回数分の平均をとって評価するので偶然の影響が小さくなる.
・評価結果からの平均,標準偏差を出すことができるので,精度の安定度がわかる
結果
http://www.str.ce.akita-u.ac.jp/~gotouhan/j2025/niwa/kfold_result.txt
正解率は84%と出ているが,95%のときや61%のときもあり,正解率にばらつきが生じている.
また,標準偏差も12.14と非常に大きく,結果の信憑性は非常に低い.
結果 source /home/kouzou/cifar-env/bin/activate device = cuda epoch: 0 loss: 1.57 test accuracy : 0.6087
epoch: 1 loss: 1.20 test accuracy : 0.7122
epoch: 2 loss: 1.04 test accuracy : 0.7680
epoch: 3 loss: 0.96 test accuracy : 0.8128
epoch: 4 loss: 0.90 test accuracy : 0.8369
epoch: 5 loss: 0.86 test accuracy : 0.8500
epoch: 6 loss: 0.82 test accuracy : 0.8585
epoch: 7 loss: 0.79 test accuracy : 0.8521
epoch: 8 loss: 0.76 test accuracy : 0.8776 Fold 1 Epoch 17 Loss=0.1429
epoch: 9 loss: 0.74 test accuracy : 0.8827 Fold 1 Epoch 17 Loss=0.1429
epoch: 10 loss: 0.72 test accuracy : 0.8805
epoch: 11 loss: 0.70 test accuracy : 0.8894
epoch: 12 loss: 0.68 test accuracy : 0.8945
epoch: 13 loss: 0.67 test accuracy : 0.8893
epoch: 14 loss: 0.65 test accuracy : 0.8965
epoch: 15 loss: 0.64 test accuracy : 0.9072
epoch: 16 loss: 0.63 test accuracy : 0.9044
epoch: 17 loss: 0.62 test accuracy : 0.9080
epoch: 18 loss: 0.61 test accuracy : 0.9096
epoch: 19 loss: 0.59 test accuracy : 0.9020
epoch: 20 loss: 0.59 test accuracy : 0.9152
epoch: 21 loss: 0.58 test accuracy : 0.9139
epoch: 22 loss: 0.57 test accuracy : 0.9219
epoch: 23 loss: 0.56 test accuracy : 0.9208
epoch: 24 loss: 0.56 test accuracy : 0.9154
epoch: 25 loss: 0.55 test accuracy : 0.9185
epoch: 26 loss: 0.55 test accuracy : 0.9225
epoch: 27 loss: 0.54 test accuracy : 0.9273
epoch: 28 loss: 0.54 test accuracy : 0.9258
epoch: 29 loss: 0.53 test accuracy : 0.9277
epoch: 30 loss: 0.53 test accuracy : 0.9249
epoch: 31 loss: 0.53 test accuracy : 0.9259
epoch: 32 loss: 0.52 test accuracy : 0.9279
epoch: 33 loss: 0.52 test accuracy : 0.9306
epoch: 34 loss: 0.52 test accuracy : 0.9314
epoch: 35 loss: 0.52 test accuracy : 0.9293
epoch: 36 loss: 0.51 test accuracy : 0.9327
epoch: 37 loss: 0.51 test accuracy : 0.9309
epoch: 38 loss: 0.51 test accuracy : 0.9327
epoch: 39 loss: 0.51 test accuracy : 0.9333
epoch: 40 loss: 0.51 test accuracy : 0.9368
epoch: 41 loss: 0.51 test accuracy : 0.9354
epoch: 42 loss: 0.51 test accuracy : 0.9363
epoch: 43 loss: 0.51 test accuracy : 0.9349
epoch: 44 loss: 0.51 test accuracy : 0.9368
epoch: 45 loss: 0.51 test accuracy : 0.9363
epoch: 46 loss: 0.51 test accuracy : 0.9359
epoch: 47 loss: 0.51 test accuracy : 0.9365
epoch: 48 loss: 0.51 test accuracy : 0.9358
epoch: 49 loss: 0.51 test accuracy : 0.9353
final train accuracy: 0.9993 final test accuracy : 0.9353
=== Per Class Accuracy ===
airplane 942/1000 (94.20%)
automobile 967/1000 (96.70%)
bird 906/1000 (90.60%)
cat 871/1000 (87.10%)
deer 940/1000 (94.00%)
dog 891/1000 (89.10%)
frog 958/1000 (95.80%)
horse 958/1000 (95.80%)
ship 967/1000 (96.70%)
truck 953/1000 (95.30%)
93.5%と若干上昇.
・さらに精度を上げるためにモデルをCNNからRasNetに変えてみた,epoch数は50で行った.
・RasNetとは:一般的なCNNにさらにショーカット連続を追加したモデル.一般的なCNNでは層を増やすと最初の方に得られた特徴の情報が 薄れてきてしまうが,RasNetはショーカット連続を追加したモデルなので最小の方の上を忘れにくい(残差連続).そのためそうが深くても高い精度をだすことができる.
結果
(cifar-env) kouzou@ii21:~$ /home/kouzou/cifar-env/bin/python /home/kouzou/python/cifar-env/cifar_cnn.py
device = cuda
epoch: 0
loss: 1.37
test accuracy : 0.5985
epoch: 1 loss: 0.89 test accuracy : 0.7110
epoch: 2 loss: 0.69 test accuracy : 0.7690
epoch: 3 loss: 0.58 test accuracy : 0.7785
epoch: 4 loss: 0.51 test accuracy : 0.8282
epoch: 5 loss: 0.45 test accuracy : 0.8177
epoch: 6 loss: 0.40 test accuracy : 0.8548
epoch: 7 loss: 0.36 test accuracy : 0.8577
epoch: 8 loss: 0.33 test accuracy : 0.8740
epoch: 9 loss: 0.30 test accuracy : 0.8850
epoch: 10 loss: 0.27 test accuracy : 0.8776
epoch: 11 loss: 0.25 test accuracy : 0.8897
epoch: 12 loss: 0.23 test accuracy : 0.8830
epoch: 13 loss: 0.21 test accuracy : 0.8981
epoch: 14 loss: 0.19 test accuracy : 0.8975
epoch: 15 loss: 0.17 test accuracy : 0.9051
epoch: 16 loss: 0.16 test accuracy : 0.9043
epoch: 17 loss: 0.14 test accuracy : 0.8972
epoch: 18 loss: 0.13 test accuracy : 0.9074
epoch: 19 loss: 0.11 test accuracy : 0.9089
epoch: 20 loss: 0.10 test accuracy : 0.9079
epoch: 21 loss: 0.10 test accuracy : 0.9157
epoch: 22 loss: 0.08 test accuracy : 0.9141
epoch: 23 loss: 0.08 test accuracy : 0.9114
epoch: 24 loss: 0.07 test accuracy : 0.9183
epoch: 25 loss: 0.06 test accuracy : 0.9208
epoch: 26 loss: 0.06 test accuracy : 0.9184
epoch: 27 loss: 0.04 test accuracy : 0.9161
epoch: 28 loss: 0.04 test accuracy : 0.9165
epoch: 29 loss: 0.04 test accuracy : 0.9226
epoch: 30 loss: 0.03 test accuracy : 0.9186
epoch: 31 loss: 0.03 test accuracy : 0.9240
epoch: 32 loss: 0.02 test accuracy : 0.9224
epoch: 33 loss: 0.02 test accuracy : 0.9208
epoch: 34 loss: 0.02 test accuracy : 0.9236
epoch: 35 loss: 0.02 test accuracy : 0.9264
epoch: 36 loss: 0.01 test accuracy : 0.9287
epoch: 37 loss: 0.01 test accuracy : 0.9276
epoch: 38 loss: 0.01 test accuracy : 0.9278
epoch: 39 loss: 0.01 test accuracy : 0.9313
epoch: 40 loss: 0.01 test accuracy : 0.9307
epoch: 41 loss: 0.01 test accuracy : 0.9305
epoch: 42 loss: 0.01 test accuracy : 0.9306
epoch: 43 loss: 0.00 test accuracy : 0.9299
epoch: 44 loss: 0.01 test accuracy : 0.9292
epoch: 45 loss: 0.00 test accuracy : 0.9302
epoch: 46 loss: 0.00 test accuracy : 0.9314
epoch: 47 loss: 0.00 test accuracy : 0.9305
epoch: 48 loss: 0.00 test accuracy : 0.9314
epoch: 49 loss: 0.00 test accuracy : 0.9320
final train accuracy: 0.9997 final test accuracy : 0.9320
=== Per Class Accuracy ===
airplane 939/1000 (93.90%)
automobile 976/1000 (97.60%)
bird 906/1000 (90.60%)
cat 836/1000 (83.60%)
deer 944/1000 (94.40%)
dog 896/1000 (89.60%)
frog 968/1000 (96.80%)
horse 951/1000 (95.10%)
ship 962/1000 (96.20%)
truck 942/1000 (94.20%)
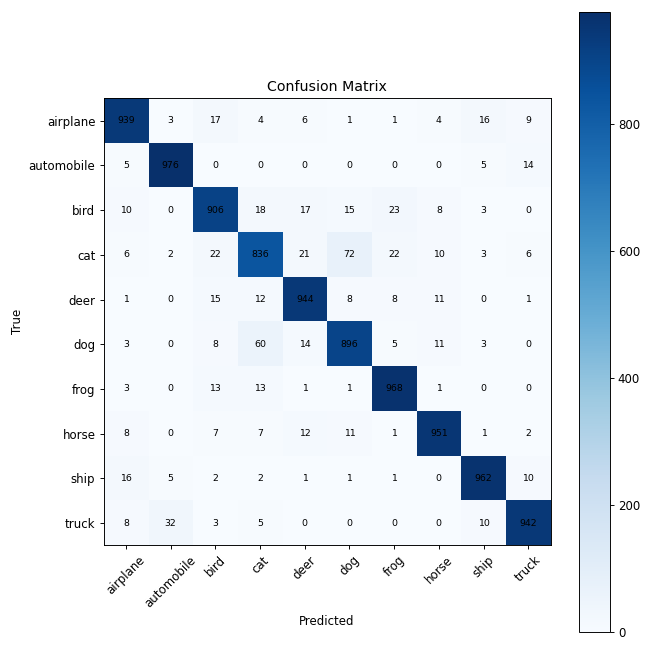

結果より精度が93%と非常に高い精度となった.混同行列や間違えた画像を見ると,間違いの殆どが犬と猫であることがわかった.
さらに精度を上げるために
・DataAugmentationに新たにcolorjitterを追加した.これにより明るさ,コントラスト,色味をランダムに変化させ,多様な画像で学習をできるようにした.
・AdamをAdamWにすることで重みが大きくなりすぎるのを防ぎ,過学習をおさえた.
・Batch Sizeを64から128に変更し,学習の安定化を図る.
・Label Smoothingを導入しモデルが極端な判断をするのを防ぐ.
・CosineAnnealingLRで後半の学習率を調整する
・1回の学習時間が長くなってきたので合間で,森井さんの日誌や機械学習の用語について調べる.
・アンサンブル学習:複数のモデルを用いて,それぞれの学習の弱点を補うことで,より精度の高い予測を行うという方法.
・混同行列のスクリプトを作成し,どれとどれが間違っているのかを可視化した.
catとdogで間違えていることがよくわかった.この問題を解決することはできないのだろうか.
・epoch数20でも実行可能であることがわかったのでDropoutとSchedulerを再び導入してみる.
結果
device = cuda
epoch: 0
loss: 1.62
test accuracy : 0.5609
epoch: 1 loss: 1.29 test accuracy : 0.5629
epoch: 2 loss: 1.17 test accuracy : 0.6620
epoch: 3 loss: 1.08 test accuracy : 0.6744
epoch: 4 loss: 1.02 test accuracy : 0.7158
epoch: 5 loss: 0.92 test accuracy : 0.7358
epoch: 6 loss: 0.89 test accuracy : 0.7507
epoch: 7 loss: 0.87 test accuracy : 0.7490
epoch: 8 loss: 0.84 test accuracy : 0.7549
epoch: 9 loss: 0.82 test accuracy : 0.7609
epoch: 10 loss: 0.77 test accuracy : 0.7770
epoch: 11 loss: 0.76 test accuracy : 0.7818
epoch: 12 loss: 0.75 test accuracy : 0.7814
epoch: 13 loss: 0.74 test accuracy : 0.7888
epoch: 14 loss: 0.73 test accuracy : 0.7921
epoch: 15 loss: 0.71 test accuracy : 0.7948
epoch: 16 loss: 0.70 test accuracy : 0.7991
epoch: 17 loss: 0.69 test accuracy : 0.7991
epoch: 18 loss: 0.69 test accuracy : 0.7997
epoch: 19 loss: 0.69 test accuracy : 0.7962
final train accuracy: 0.8106
final test accuracy : 0.7962
79%と上昇した.
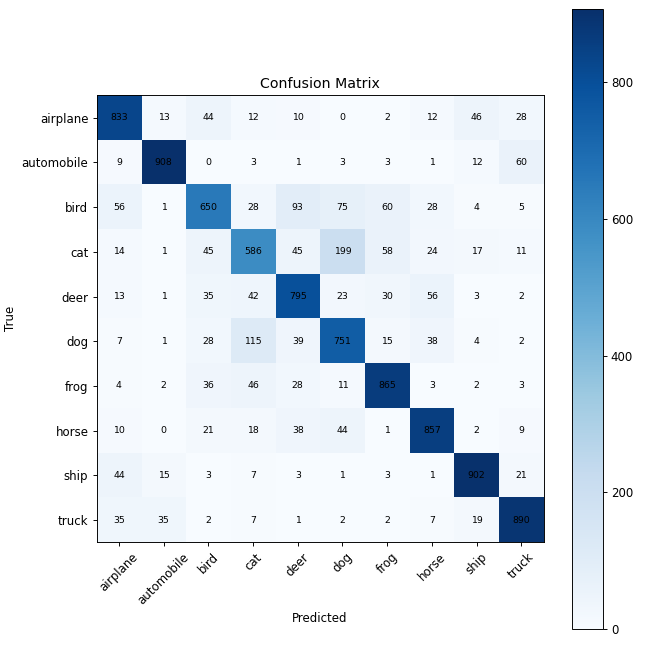
・各クラスごとの正解率を見てみる.
=== Per Class Accuracy ===
airplane 837/1000 (83.70%)
automobile 923/1000 (92.30%)
bird 648/1000 (64.80%)
cat 612/1000 (61.20%)
deer 800/1000 (80.00%)
dog 729/1000 (72.90%)
frog 878/1000 (87.80%)
horse 839/1000 (83.90%)
ship 906/1000 (90.60%)
truck 876/1000 (87.60%)
見ると乗り物系は非常に正解率が高いのに対して,bird,cat,dogは低い.
・ロス数を平均化したほうがのちのち都合が良いので平均化する.
・train accuracyを毎回表示していると実行に時間がかかるのでやめる.
・Dropoutを導入してモデルに応用力をつける.
・Schedulerを導入して学習率を意図的に下げ,学習の調整を細かくする.
Dropoutとは:
Dropoutとはニューラルネットワークの学習中に、各層の一部のニューロンをランダムに無効化する手法である.
イメージは学習のたびにネットワークの一部を休ませることでさまざまな経路で学習させる方法.これにより,特定のニューロンへの依存が減るため,モデルの汎用性が高まったり,過学習を防いだりといった効果が期待できる.
結果
(cifar-env) kouzou@ii21:~$ /home/kouzou/cifar-env/bin/python /home/kouzou/python/cifar-env/cifar_cnn.py
epoch: 0
loss: 1.72
test accuracy : 0.5144
epoch: 1 loss: 1.49 test accuracy : 0.5245
epoch: 2 loss: 1.38 test accuracy : 0.6027
epoch: 3 loss: 1.32 test accuracy : 0.6275
epoch: 4 loss: 1.28 test accuracy : 0.6424
epoch: 5 loss: 1.20 test accuracy : 0.6842
epoch: 6 loss: 1.17 test accuracy : 0.6899
epoch: 7 loss: 1.15 test accuracy : 0.6941
epoch: 8 loss: 1.13 test accuracy : 0.6966
epoch: 9 loss: 1.12 test accuracy : 0.7020
final train accuracy: 0.6789
final test accuracy : 0.7020
精度が上がらない,epochが10と少ないのに学習率を下げたからと考えられるのでSchedulerを一回やめる,Dropoutも一回やめて,実行に時間はかかるが,epoch数を20に増やしてみる.
結果
(cifar-env) kouzou@ii21:~$ /home/kouzou/cifar-env/bin/python /home/kouzou/python/cifar-env/cifar_cnn.py
device = cuda
epoch: 0
loss: 1.47
test accuracy : 0.5780
epoch: 1 loss: 1.16 test accuracy : 0.6445
epoch: 2 loss: 1.05 test accuracy : 0.6615
epoch: 3 loss: 0.98 test accuracy : 0.6726
epoch: 4 loss: 0.92 test accuracy : 0.7146
epoch: 5 loss: 0.89 test accuracy : 0.7112
epoch: 6 loss: 0.86 test accuracy : 0.7355
epoch: 7 loss: 0.83 test accuracy : 0.7273
epoch: 8 loss: 0.81 test accuracy : 0.7467
epoch: 9 loss: 0.79 test accuracy : 0.7415
epoch: 10 loss: 0.77 test accuracy : 0.7508
epoch: 11 loss: 0.75 test accuracy : 0.7490
epoch: 12 loss: 0.74 test accuracy : 0.7582
epoch: 13 loss: 0.72 test accuracy : 0.7664
epoch: 14 loss: 0.71 test accuracy : 0.7587
epoch: 15 loss: 0.70 test accuracy : 0.7544
epoch: 16 loss: 0.69 test accuracy : 0.7779
epoch: 17 loss: 0.68 test accuracy : 0.7691
epoch: 18 loss: 0.66 test accuracy : 0.7787
epoch: 19 loss: 0.66 test accuracy : 0.7784
final train accuracy: 0.7683
final test accuracy : 0.7784
77%と精度が上がった.
次は80%以上まで上げたい.よって3層目の畳み込み層を追加してみることにした.
結果
kouzou@ii21:~$ /home/kouzou/cifar-env/bin/python /home/kouzou/python/cifar-env/cifar_cnn.py
source /home/kouzou/cifar-env/bin/activate
device = cuda epoch: 0 loss: 1.38 test accuracy : 0.6097
epoch: 1 loss: 1.01 test accuracy : 0.6555
epoch: 2 loss: 0.89 test accuracy : 0.7165
epoch: 3 loss: 0.81 test accuracy : 0.7134
epoch: 4 loss: 0.76 test accuracy : 0.7484
epoch: 5 loss: 0.71 test accuracy : 0.7624
epoch: 6 loss: 0.67 test accuracy : 0.7605
epoch: 7 loss: 0.65 test accuracy : 0.7712
epoch: 8 loss: 0.62 test accuracy : 0.7708
epoch: 9 loss: 0.60 test accuracy : 0.7969
epoch: 10 loss: 0.58 test accuracy : 0.7918
epoch: 11 loss: 0.56 test accuracy : 0.8075
epoch: 12 loss: 0.55 test accuracy : 0.7877
epoch: 13 loss: 0.53 test accuracy : 0.8163
epoch: 14 loss: 0.52 test accuracy : 0.8106
epoch: 15 loss: 0.51 test accuracy : 0.8187
epoch: 16 loss: 0.49 test accuracy : 0.8118
epoch: 17 loss: 0.48 test accuracy : 0.8127
epoch: 18 loss: 0.47 test accuracy : 0.8176
epoch: 19 loss: 0.46 test accuracy : 0.8307
final train accuracy: 0.8537
final test accuracy : 0.8307
83%まで精度が上がった.
epoch数を10にして再び学習
poch: 0
loss: 1454.0281460285187
train accuracy: 0.37928
test accuracy : 0.3776
epoch: 1 loss: 1312.5663577318192 train accuracy: 0.43784 test accuracy : 0.4368
epoch: 2 loss: 1255.8324360847473 train accuracy: 0.44384 test accuracy : 0.4342
epoch: 3 loss: 1225.7701717615128 train accuracy: 0.4555 test accuracy : 0.4453
epoch: 4 loss: 1197.299763083458 train accuracy: 0.46088 test accuracy : 0.4494
epoch: 5 loss: 1176.6848516464233 train accuracy: 0.45176 test accuracy : 0.439
epoch: 6 loss: 1155.949428319931 train accuracy: 0.4852 test accuracy : 0.4715
epoch: 7 loss: 1145.0654866695404 train accuracy: 0.49966 test accuracy : 0.4809
epoch: 8 loss: 1131.507185101509 train accuracy: 0.4894 test accuracy : 0.4708
epoch: 9 loss: 1119.446041584015 train accuracy: 0.49018 test accuracy : 0.4643
epoch数7でテストデータの正解率が頭打ちになり,8以降から下がっているため,過学習が行われてしまっている.したがってこれからはepoch数を7とする.
モデルをCNNに変えてみた.epoch数は6.
結果
kouzou@ii21:~$ /home/kouzou/cifar-env/bin/python /home/kouzou/python/cifar-env/cifar_cnn.py
epoch: 0
loss: 1139.25
train accuracy: 0.5978
test accuracy : 0.5882
epoch: 1 loss: 837.40 train accuracy: 0.6725 test accuracy : 0.6484
epoch: 2 loss: 708.00 train accuracy: 0.7027 test accuracy : 0.6608
epoch: 3 loss: 624.75 train accuracy: 0.7513 test accuracy : 0.6909
epoch: 4 loss: 556.14 train accuracy: 0.7853 test accuracy : 0.7007
epoch: 5 loss: 479.45 train accuracy: 0.8171 test accuracy : 0.7008
正解率は70%まで上昇した.間違えた画像をいくつか見てみたが法則性はなさそうだった.
更に精度を上げるためにデータを拡張してみる.データの拡張とは,たとえば1つの犬の画像を左右反転したり切り取って位置を変えたりして様々な味方をすることでデータを増やすという方法.
結果
epoch: 0
loss: 1143.16
train accuracy: 0.5662
test accuracy : 0.5652
epoch: 1 loss: 867.45 train accuracy: 0.6465 test accuracy : 0.6402
epoch: 2 loss: 768.89 train accuracy: 0.6578 test accuracy : 0.6424
epoch: 3 loss: 703.50 train accuracy: 0.6845 test accuracy : 0.6696
epoch: 4 loss: 662.69 train accuracy: 0.7149 test accuracy : 0.6994
epoch: 5 loss: 625.14 train accuracy: 0.7345 test accuracy : 0.7150
epoch: 6 loss: 602.43 train accuracy: 0.7368 test accuracy : 0.7216
epoch: 7 loss: 573.49 train accuracy: 0.7539 test accuracy : 0.7315
epoch: 8 loss: 557.15 train accuracy: 0.7562 test accuracy : 0.7317
epoch: 9 loss: 544.22 train accuracy: 0.7579 test accuracy : 0.7293
正解率が2〜3%上昇した.
BatchNormを入れてみる.これを入れると中間層でスケールを揃えてくれる.
結果
epoch: 0
loss: 1146.65
train accuracy: 0.5569
test accuracy : 0.5911
epoch: 1 loss: 908.52 train accuracy: 0.6080 test accuracy : 0.6496
epoch: 2 loss: 818.68 train accuracy: 0.6324 test accuracy : 0.6592
epoch: 3 loss: 762.90 train accuracy: 0.6769 test accuracy : 0.7033
epoch: 4 loss: 723.64 train accuracy: 0.6831 test accuracy : 0.7015
epoch: 5 loss: 691.66 train accuracy: 0.7062 test accuracy : 0.7291
epoch: 6 loss: 669.03 train accuracy: 0.7056 test accuracy : 0.7216
epoch: 7 loss: 642.19 train accuracy: 0.7261 test accuracy : 0.7416
epoch: 8 loss: 628.23 train accuracy: 0.7339 test accuracy : 0.7517
epoch: 9 loss: 608.50 train accuracy: 0.7405 test accuracy : 0.7526
2%ほど正解率が上がった.
CIFAR-10という動物や車,飛行機の画像が大量にあるデータをつかって機械学習の練習をした.
画像例

まずは代表的なNNであるMLPをつかって行った.epochは3で行った.
結果:
epoch: 0
loss: 1452.5976511240005
accuracy: 0.36034
epoch: 1 loss: 1307.6552993059158 accuracy: 0.40218
epoch: 2 loss: 1258.6369264125824 accuracy: 0.45128
正解率45%と非常に低い.
間違えた画像の一部を表示した.

ここから考察するに間違いに法則性がないため単純に精度が低い.
明日やること:CNNでやってみる,またそこからさらに正解率を上げるにはどうしたらいいか考える.
自分が手書きで書いた星を見せたときどんな数字だとモデルが判断するのか試してみた.

結果,8と判断した.当然星なので8ではない.このモデルはどんなに数字とはちがくても0〜9のどれかで答えを出すようになっているので,次に確信度0.7以下では数字ではない可能性があると判断できるようにした.
しかし,結果は8で確信度は0.994つまり99.4%と非常に高い確信度で8と判断してしまったので,何が原因か考えている.
他の数字ではない画像で試してみた.


これらの画像も確信度99%で0,98%で4と判断されてしまった.
・なぜ,数字ではない画像を見せたときに確信度が0.7以下とならず,99%で何らかの数字が選ばれるかの考察
まず,いろいろな数字ではない図形を見せても99%で何らかの数字だと判断される時点で,このモデルがおかしいのではなく,正常に動いた結果そのように判断されていると考察できる.
では,なぜ99%で何らかの数字が出るのか考えてみた.今回のモデルの場合の確信度とはモデルがこの数字だと判断したときの自信の度合いを表す.つまり0か6かで悩んでいた場合は確信度は低くなるということである.このことから今回,数字ではない画像を見せたとき,例えば渦巻の部分的な特徴が0の部分的な特徴と似ていただけでなく他の数字だと0に比べて似ている特徴が少なかったため0が圧倒的有力候補になってしまったと考えられる.
試しに,0か6か判別しづらそうな画像を見せてみた.

この結果は’数字ではない可能性があります’と出た!つまり上記の考察のもとで考えるとモデルは0か6かで迷って確信度が0.7よりも低くなったため数字ではない可能性がありますと出たと考えられる.
よって数字ではない画像を数字ではないと判別するには,学習データに大量の数字ではないデータを新たに取り入れ,クラス分けを0〜9だけでなく+unknownのようにする必要があると考察できる.
そもそも教師あり学習は特徴量と正解データによって正解を予想するので,学習させてないパターンの画像を見せてもうまく行くわけがないと思った.今回の練習で教師あり学習の基礎を再び思い出すことができた.
今回は自分の手書きの数字4に線や点などの障害物を加えたときに,うまく4と判別できるか試してみる.さらに新たに確信率というものを加えた.確信度とは,モデルが数字を判断するにあたってどれくらいの自信をもって判断しているかの指標である.
たとえば自分が手書きで書いた数字6でテストした結果コレは6ですと判断したとする.一見すると正解しているので良いと思われるが,確信度が0.60,つまり60%であった場合,モデルはあまり自信ないけど多分6というように判断しているということになる.つまり,答えを出す過程がわかるのでより解像度を上げやすい.

結果:ノイズをいれても4と判断してくれた確信度は100%と非常に良い.
テスト精度は99.06%と高いが,間違えているところを見ると0と6で間違えていた.←これは人間でも間違えやすい
明日やること,数字ではない図形を見てどう判断するのか見てみる.このモデルは0〜9のどれかの数字であるとしか判断することができないため,数字ではないものを見せたらどうなるのか見てみたい.
昨日よりもさらに精度を上げるためにエポック数を3から10に増やした.(しかし,増やしすぎると初見データに弱くなるという過学習が生じるので注意)
結果は97.94%と上昇した.
・更に精度を上げるためにCNNに変えてみた.
結果,テスト精度が99.07%まで,上昇した.今までlossが低くて20くらいだったが,5くらいまで下がった.
・CNN(畳み込みニューラルネットワークとは)
NNの一種で画像処理に特化している.NNは画像を単なる数値として処理しているのでピクセルの並びそのものを覚えているというイメージ.したがって画像の中の対象の位置,場所にとても強いわけではない.一方でCNNは特徴を局所で見る,画像の中の対象の特徴を部品として見るので位置がちがくても対応することができる.つまり,NNは場所ごとの意味を持たないが,CNNは特徴のパターンを学んでいるため位置に強いのである.
CNNは3つの要素で構成されている.
・畳み込み層:局所的な部分の特徴を見つける.小さなフィルター(重み行列)をスライドさせ,エッジを見つける)
・プーリング層:特徴を圧縮する.画像データは大量の数値の塊である,そこで局所的な領域の行列の最大値だけを残すことで情報量を簡素化し,小さな誤差や不要な情報を排除する.
・全結合層:畳み込み+プーリングによって得られた特徴の集合からすべての特徴を重み付きで計算して最終的な判断を下す.
MNISTというものを用いて機械学習の練習をした.
・MNISTとは
MNISTとは、機械学習や画像認識の分野でよく使われる有名なデータセット.MNISTは、「0〜9の手書き数字画像」を集めたデータセットで、主に画像分類アルゴリズムの学習・評価に使われる~
具体的には:
0〜9の数字(10クラス)
白黒の小さな画像(28×28ピクセル)
学習用に約60,000枚、テスト用に約10,000枚
という構成になっている.
・今回使ったモデル:ニューラルネット
・ニューラルネットが画像処理に強い理由
| 画像 | ニューラルネット |
| ---------- | ------------ |
| 点が近いと線になる | 近い情報から特徴を作る |
| 線が集まって形になる | 特徴を積み上げて形になる |
なので相性が良い.
例えば決定木では位置や形に弱く,質問を投げるだけで法則を見つけ出すのは非常に難しい.
ニューラルネットは層に分けて画像の特徴を計算するのでうまく行きやすい.
・6万個のデータを3回学習させてできたモデルのテスト精度は96.92%と高い数値であった.
・次に自分が手書きで書いた数字「3」を学習させたモデルに見せてちゃんと3と判別するのか試してみる.

結果は3とでて,当てることに成功した.テスト精度は97.22%だった.
・欠損値が欠けているとき,そのデータが時系列データのとき,欠損値の穴埋めは線形補間が有効.時系列データには「相互に依存する」という特徴があるため欠損値の前後の値をもとに欠損値を予測することは非常に有効.
・前処理の段階で,欠損値を予測するために機械学習を行うのも有効.
・axis=0 → 縦方向(行をまたぐ)
・axis=1 → 横方向(列をまたぐ)
・前回まではホールドアウト法によってデータをテストデータと訓練データに分割したが,トライ&エラーを繰り返しているうちにテストデータに都合がいいようにチューニングしていると言える.
→したがってこの問題に対処するために,
①学習に使用するデータ
②学習には使用せずにチューニングの参考に使用するデータ
③チューニングを行った最終的な学習済みモデルに対して予測性能を評価するためのテストデータ
の3つに分割する.
・使用する特徴量を絞り込む際,はずれ値をチェックしてから,相関係数をチェック.理由はこの順番を逆で行うと相関係数が外れ値の影響を受けてしまうから.
・重回帰分析ではAIによってつくられた計算式の係数の大きさでそれらの特徴量の影響度を比較するが影響度が大きいとはいえ,その特徴量を1増やす労力が非常に大変で結果,係数は小さいがその特徴量のほうが影響を出しやすいという場合が存在する.
model = tree.DecisionTreeClassifier(max_depth = 5, random_state = 0,class_weight ='balanced')
は不均衡データで比率の大きいデータの影響力を小さくし,比率の小さいデータの影響力を大きくするため分岐条件を考える際の影響度という点で均一になり,予測性能の高いモデルを作れる確率が上がる.
mean()
すると文字列列を自動無視してくれました。
今の pandas は:
「文字列があるならエラーにする」
という仕様になっています。
今後のコツ
groupby().mean() を使うときは、
['Age'] ['Fare'] ['Survived']
みたいに、
「どの数値列を平均するか」
を明示すると安全です。

今まで扱っていたデータは(例)アヤメの種類分別 では3種類の正解データがそれぞれ50種類均等にあったが,今回行う客船沈没事故での生存予測では正解データである死亡者データが549件,生存者データが342件と正解データの件数の比率に差が生じている. このようなデータを不均衡データという.
・決定木モデルは他のモデルに比べ,外れ値の影響を受けにくい.
例えば生存者データが5%,死亡者データが95%であった場合,モデルは法則など関係なくとりあえず死亡とすれば正解してしまうため,よくない.
明日以降は例題のコードを一から打つのではなく,修正だけしていく
